ChatGLM2-6B! 我跑通啦!(windows系统)
- 1. 跑通了啥?
- 2. 咋跑通的?
- 2.1 ChatGLM2-6B本地部署
- 2.2 ChatGLM2-6B本地微调
- 2.3 小结
- 3. 打算做什么?
1. 跑通了啥?
记录一下此时此刻,2023年7月8日22点04,从ChatGLM2-6B在7月4日开放了ptuning到此时此刻,ChatGLM2-6B的微调终于被哥们跑通了!
从本地部署ChatGLM2-6B到本地进行P-tuning微调,再到最后的模型检测,哥们全跑通了!
2. 咋跑通的?
2.1 ChatGLM2-6B本地部署
这里非常感谢ChatGLM2-6B|开源本地化语言模型这篇博客!因为我布置环境,本地部署完全按照这个博客来的,而且他/她还贴心地帮我把要从huggingface上下载巨慢的内容下载打包好了,真的是爱了!
这里要提醒的是,要注意文件目录严格按照这个博客来,可以免除很多麻烦!
同时这篇文章提到源码修改也是非常有意义的,这和windows系统解析符号有关,后面的模型检测中,可能还会遇见这个错误!
本地部署相对麻烦的环节是pytorch的安装
我也是征战pytorch和tensorflow安装战场多年,虽然我用的服务器很高级,但是在我使用之前就下载了一个cuda是10.2版本,这可把我愁坏了。查阅版本信息可以点这个链接,可以发现10.2GPU最高安装版本是pytorch1.12.1,于是我先头铁下载了这个
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=10.2 -c pytorch
没想到的是,下载的时候表面上是GPU版本,但是G!!! 下载下来是cpu版的,于是我铤而走险,像赌徒一样,试了试pytorch1.11.0,cuda版本是11.3的
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 cudatoolkit=11.3 -c pytorch
令人惊讶的是,成了!!!标志是下载的时候,后面的注释的内容不是cpu**,而是cuda**
所以我大胆推测,pytorch的驱动核心在于,cudatoolkit的版本,只要电脑可以驱动cudatoolkit的版本即可,可以通过尝试这些代码,观察下载内容是 cpu** 还是 cuda**来确定下载的版本是不是正确的。
网上又说,torch最好是2.0.0以上,按照我的经验,不需要! 我transformer的版本是4.30,这是chatglm2-6b要求的,和chatglm-6b不一样。
最后告诉大家一个我尝试的结果:10.2的cuda 应该最高支持到pytorch的1.10.*这个系列
最后在提醒一下大家,按照上述文章,最好每一步都一样,是可以一边成功的。顺序也可以按照上述要求。
年纪大,爱唠叨,说了好几遍最后,但是还有一件事情怕大家疑惑,那就是如果你,conda list,你会发现这个现象:
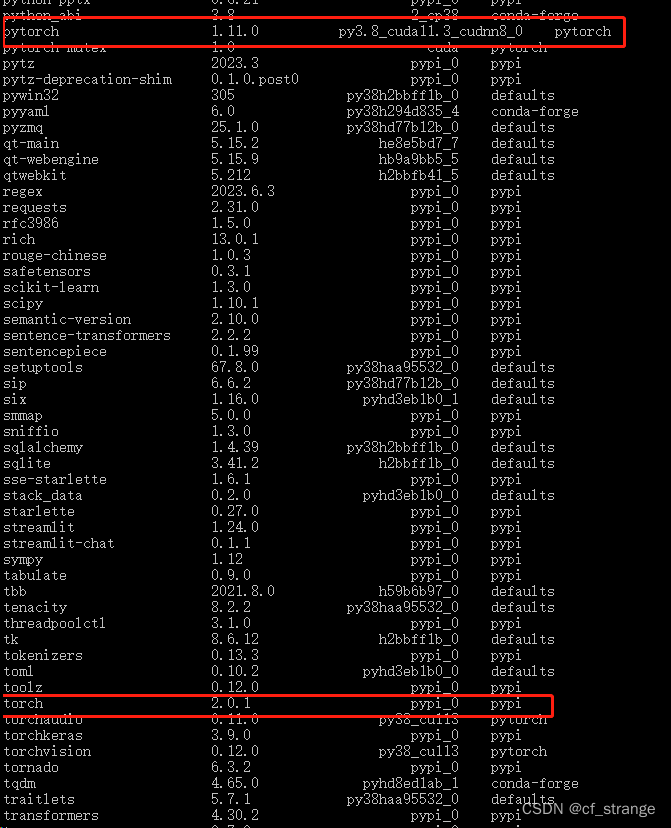
既有一个torch也有一个pytorch,哈哈,而且版本不一样,经过我的观察,torch是通过 pip install -r requirements.txt下载的,pytorch是通过conda下载的,但是两者分别的作用机理,我也不清楚,但是我暂时的结论是,两者不冲突,而且似乎以conda下载那个为主,也希望有懂这个的小伙伴或者大伙伴可以指导一下!
2.2 ChatGLM2-6B本地微调
本地微调要感谢B站up主AI李大鹅!他的视频使用P-Tuning微调Chatglm2-6B,喂饭级教程给了我很大的启发。视频只有6分钟,但是我研究他的内容用了2天吧。下面把我遇到的一些困难和心得介绍一下。
首先是系统问题,这就是我为什么在开头强调这是windows系统的解决方案,因为和linux真的不一样,官方提供的文档,是基于shell脚本的,在windows的cmd不可以直接运行,哪怕是我用git bash 也出现了问题。视频中给出 了一个解决方案——利用.bat文件,可以实现。
train.bat代码如下
set PRE_SEQ_LEN=128
set LR=2e-2
python main.py ^
--do_train ^
--train_file train.json ^
--validation_file dev.json ^
--preprocessing_num_workers 10 ^
--prompt_column content ^
--response_column summary ^
--overwrite_cache ^
--model_name_or_path THUDM/chatglm2-6b ^
--output_dir output/adgen-chatglm2-6b-pt-%PRE_SEQ_LEN%-%LR% ^
--overwrite_output_dir ^
--max_source_length 64 ^
--max_target_length 128 ^
--per_device_train_batch_size 1 ^
--per_device_eval_batch_size 1 ^
--gradient_accumulation_steps 16 ^
--predict_with_generate ^
--max_steps 3000 ^
--logging_steps 10 ^
--save_steps 1000 ^
--learning_rate %LR% ^
--pre_seq_len %PRE_SEQ_LEN% ^
--quantization_bit 4
当然这里的很多参数是可以调整的。
在cmd中按照如下步骤运行(下面是我的运行步骤,要根据自己的文件目录进行调整)
- cd /d E:\openai.wiki\ChatGLM2-6B
- conda activate E:\openai.wiki\ChatGLM2-6B\ENV
- cd ptuning
- train.bat
当然,要注意train.bat中训练文件train.json和推理文件evaluate.json的位置
在运行train.bat时,我出现了一个困恼了我一下午的bug,
RuntimeError: Default process group has not been initialized, please make sure to call
init_process_group.
这个错误我估计很多兄弟应该不会出现,但是因为用的服务器太高级了,三块独立显卡,导致了代码优先进行并行训练,但是这些我不知道该怎么处理,只能去蒙,最后蒙到了一个办法,分享给同样遇到这个问题的朋友
在main.py函数中,添加下列内容
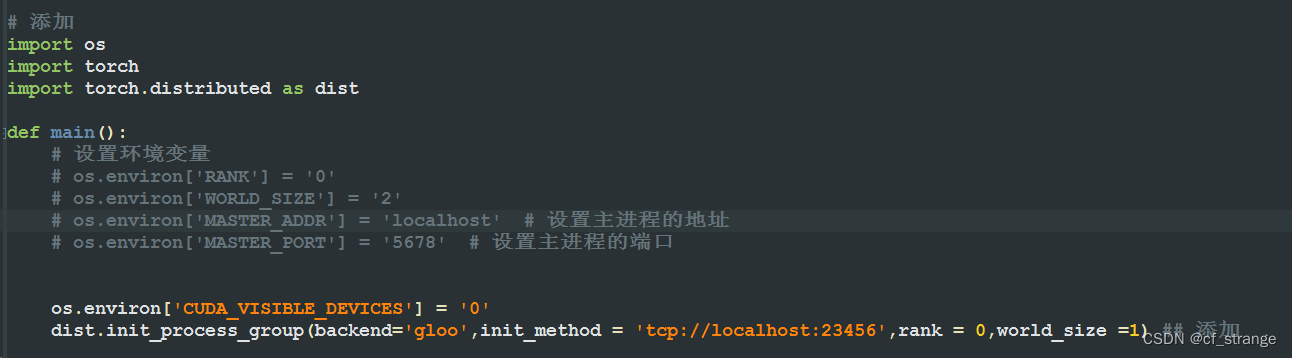
这样应该就ok了,真的很神奇!
我还遇见了一个错误
AttributeError: 'Seq2SeqTrainer' object has no attribute 'is_deepspeed_enabled'
这个错误要修改文件在这个目录

在840行左右,一个控制学习率的函数中进行修改,我采用非常鲁莽方式
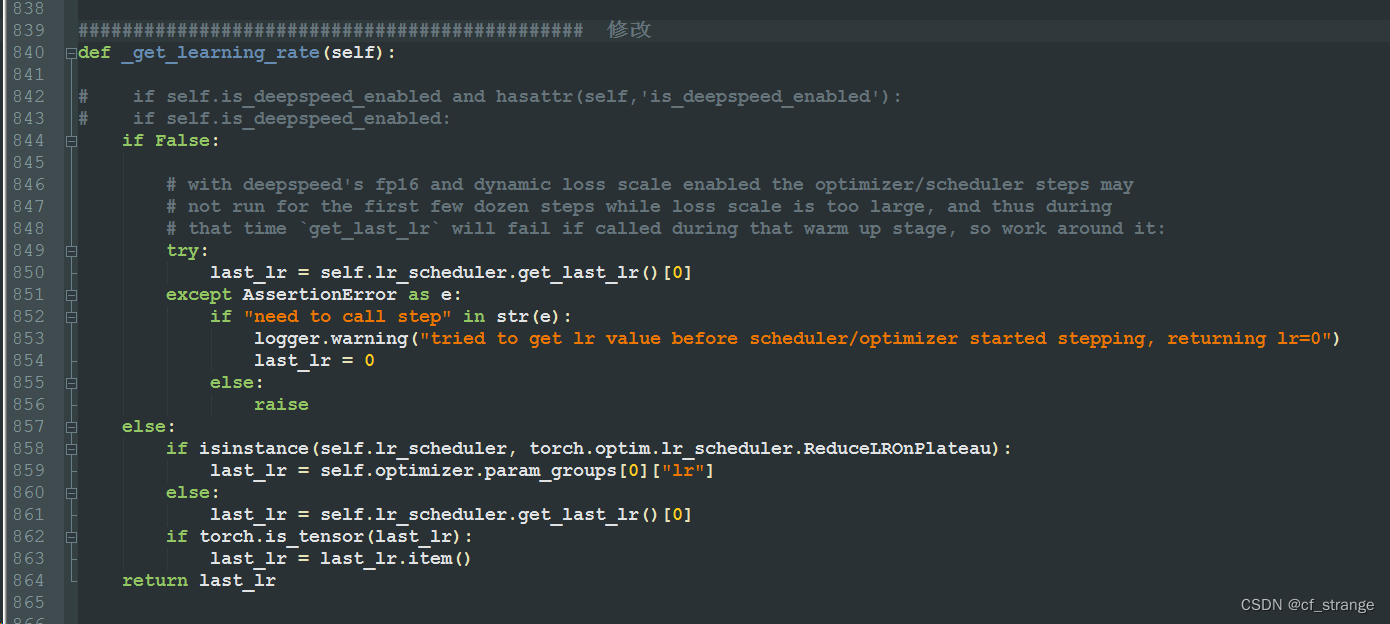
直接把判断的上半部分写成了False,这样避开了这个参数的调用。这个问题个人应该没有很好的解决办法,只能祈求自己不会出现这个报错,或者就按照我的方法来,经过我的实践,这是ok的!
我大概训练了2个小时,时间还可以!
训练完了是推理部分,下面是推理evaluate.bat的代码
set PRE_SEQ_LEN=128
set CHECKPOINT=adgen-chatglm2-6b-pt-128-2e-2
set STEP=3000
set NUM_GPUS=1
python main.py ^
--do_predict ^
--validation_file dev.json ^
--test_file dev.json ^
--overwrite_cache ^
--prompt_column content ^
--response_column summary ^
--model_name_or_path THUDM/chatglm2-6b ^
--ptuning_checkpoint ./output/%CHECKPOINT%/checkpoint-%STEP% ^
--output_dir ./output/%CHECKPOINT% ^
--overwrite_output_dir ^
--max_source_length 64 ^
--max_target_length 64 ^
--per_device_eval_batch_size 1 ^
--predict_with_generate ^
--pre_seq_len %PRE_SEQ_LEN% ^
--quantization_bit 4
推理过程,很快,而且0bug,幸福!
最后是模型检测阶段
model_test.py代码如下(这是要自己写的,补充进去)(注意地址需要修改)
from transformers import AutoConfig,AutoModel,AutoTokenizer
import os,torch
CHECKPOINT_PATH = "E:\openai.wiki\ChatGLM2-6B\ptuning\output/adgen-chatglm2-6b-pt-128-2e-2\checkpoint-3000"
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained('THUDM/chatglm2-6b',trust_remote_code = True)
# 加载P-Tuning的checkpoint
config = AutoConfig.from_pretrained("THUDM/chatglm2-6b",trust_remote_code = True,pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b",config=config,trust_remote_code = True)
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH,'pytorch_model.bin'))
print(prefix_state_dict)
new_prefix_state_dict = {}
for k,v in prefix_state_dict.items():
if k.startswith('transformers.prefix_encoder.'):
new_prefix_state_dict[k[len('transformers.prefix_encoder.'):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict,False)
model = model.half().cuda()
model.transformer.prefix_encoder.float().cuda()
model = model.eval()
response,history = model.chat(tokenizer,'宽松的衣服质感如何',history=[])
print(response)
可以观察到CHECKPOINT_PATH = "E:\openai.wiki\ChatGLM2-6B\ptuning\output/adgen-chatglm2-6b-pt-128-2e-2\checkpoint-3000"中很细节的把\adgen** 修改成了/adgen**,就是第一篇博客中提到转义问题。
这是遇到的最后一个问题,

因为AI李大鹅提供的源代码中,下面这一句是没有False的。
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict,False)
没有False我就会出现上述的报错。所以我还是一种选择忽略错误的方式,在结尾加了一个False。这不影响最后的运行和加载。
最后成功的标志:
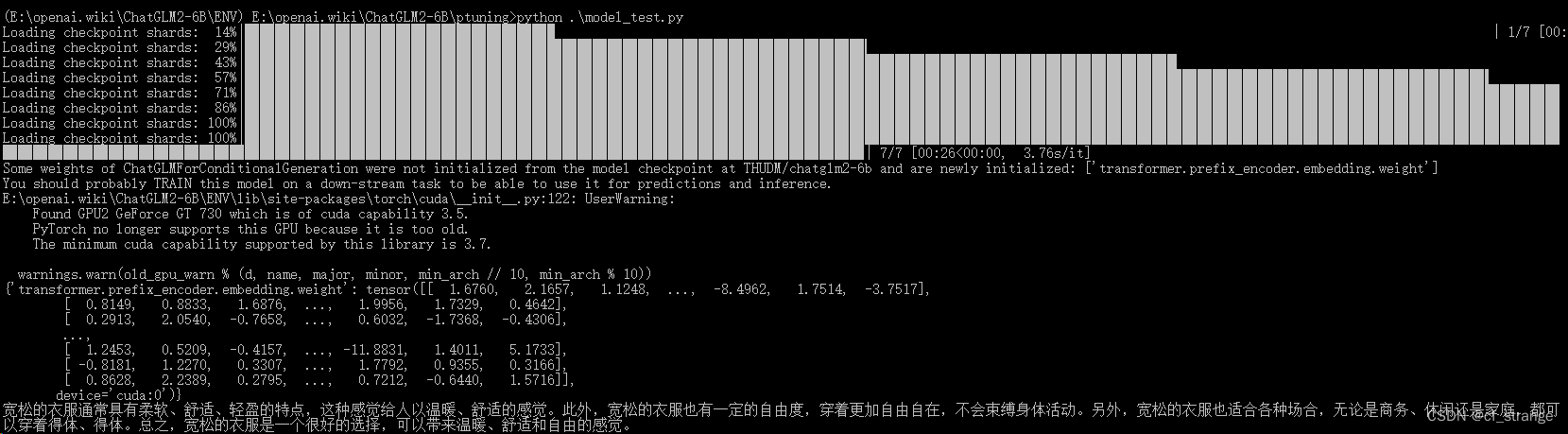
2.3 小结
使用大模型,就会遇见这些各种各样的问题,这既让我体会到了python这种脚本语言的便捷,同时让我感受到了版本的混乱,而且这种别人写好的代码,如何进行debug,我认为这是未来走向工作岗位或者科研岗,非常重要的技能!
以上内容也仅仅是我自己遇见的问题,可能还会有别的问题,可能试着按照我这种忽略法来解决,毕竟,能跑起来就行!结果慢慢考虑。
3. 打算做什么?
有了这套技术,我的下一步目标就是,收集土建行业数据,构建土建行业大模型。我了解的还不够深入,看论坛看到了一些炫酷的名词,比如历史遗忘等等,暂时我也不懂这些,希望在下一步的研究中,可以继续深入研究,加油!
欢迎小伙伴和大伙伴们可以积极留言自己搞这一套遇到的问题,我可以尽力帮助大家,同时收集大家的问题,让大模型的门槛越来越低!真正走向大众!




](https://img-blog.csdnimg.cn/direct/c68f0d99341f461ca94e024fe056db23.png)