restful
软件定时器
jedec
合并查询
压力测试
自述
二维码
RK3399
语音
产品运营
雨滴传感器
SphereNet
监控
大端
论文选题
visualstudio
业界资讯
C
svn
数字IC设计
大语言模型
2024/4/12 4:53:44
NLP实践——LLM生成过程中防止重复循环
NLP实践——LLM生成过程中防止重复 1. 准备工作2. 问题分析3. 创建processor3.1 防止重复生成的processor3.2 防止数字无规则循环的processor 4. 使用 本文介绍如何使用LogitsProcessor避免大模型在生成过程中出现重复的问题。
1. 准备工作
首先实例化一个大模型,…

【AI视野·今日NLP 自然语言处理论文速览 第四十四期】Fri, 29 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 29 Sep 2023 Totally 45 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
MindShift: Leveraging Large Language Models for Mental-States-Based Problematic Smartphone Use Interve…
LLM之Colossal-LLaMA-2:Colossal-LLaMA-2的简介、安装、使用方法之详细攻略
LLM之Colossal-LLaMA-2:Colossal-LLaMA-2的简介、安装、使用方法之详细攻略 导读:2023年9月25日,Colossal-AI团队推出了开源模型Colossal-LLaMA-2-7B-base。Colossal-LLaMA-2项目的技术细节,主要核心要点总结如下: >> 数据处…

【AI视野·今日NLP 自然语言处理论文速览 第七十八期】Wed, 17 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 17 Jan 2024 (showing first 100 of 163 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Deductive Closure Training of Language Models for Coherence, Accur…

【AI视野·今日NLP 自然语言处理论文速览 第七十四期】Wed, 10 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 10 Jan 2024 Totally 38 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Model Editing Can Hurt General Abilities of Large Language Models Authors Jia Chen Gu, Hao Xiang Xu, J…

用通俗易懂的方式讲解:一文讲透主流大语言模型的技术原理细节
大家好,今天的文章分享三个方面的内容: 1、比较 LLaMA、ChatGLM、Falcon 等大语言模型的细节:tokenizer、位置编码、Layer Normalization、激活函数等。 2、大语言模型的分布式训练技术:数据并行、张量模型并行、流水线并行、3D …

【LLM】大型语言模型:2023年完整指南
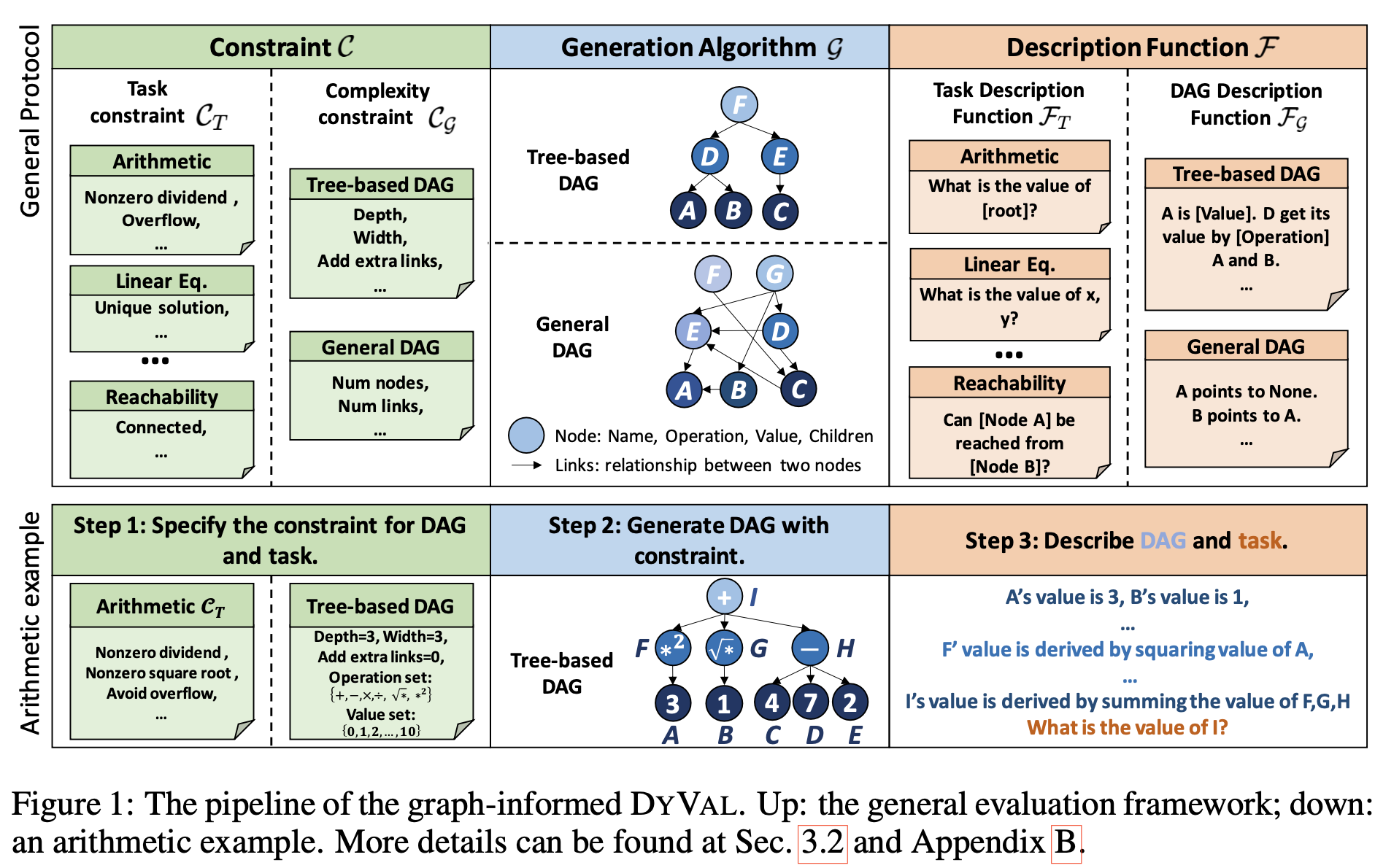
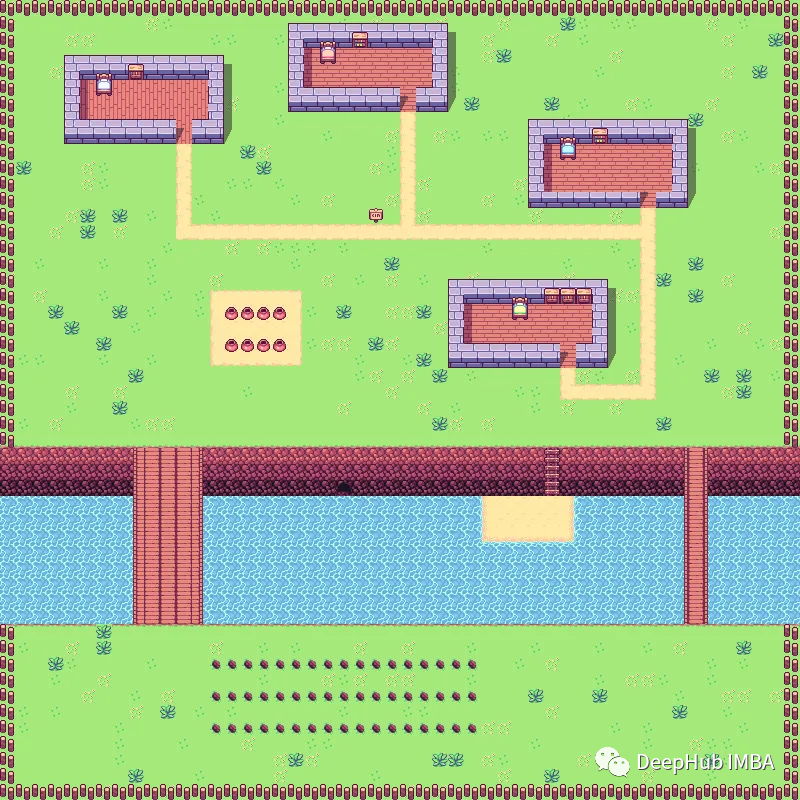
Figure 1: Search volumes for “large language models”
近几个月来,大型语言模型(LLM)引起了很大的轰动(见图1)。这种需求导致了利用语言模型的网站和解决方案的不断开发。ChatGPT在2023年1月创下了用户群增长最快…
论文笔记 | Nature 2023 FunSearch:利用大语言模型在数学科学领域探索新的发现
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 科学中有许多难以解决的问题,这些问题难以获得确切解答,但却相对容易进行验证。在数学和计算机科学领域,这类问题被称为 NP 完全优化问题(NP-complete optimization pr…
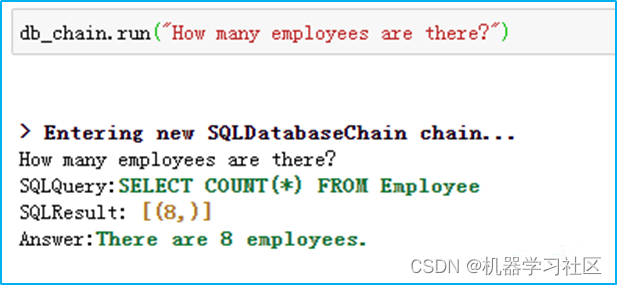
大模型LLM在 Text2SQL 上的应用实践
一、前言
目前,大模型的一个热门应用方向Text2SQL,它可以帮助用户快速生成想要查询的SQL语句,再结合可视化技术可以降低使用数据的门槛,更便捷的支持决策。本文将从以下四个方面介绍LLM在Text2SQL应用上的基础实践。
Text2SQL概…
面向 NLP 任务的大模型 Prompt 设计
很久之前,我们介绍到,prompt是影响下游任务的关键所在,当我们在应用chatgpt进行nlp任务落地时,如何选择合适的prompt,对于SFT以及推理环节尤为重要。
不过,硬想不是办法,我们可以充分参考开源的…

一种全新且灵活的 Prompt 对齐优化技术
并非所有人都熟知如何与 LLM 进行高效交流。
一种方案是,人向模型对齐。 于是有了 「Prompt工程师」这一岗位,专门撰写适配 LLM 的 Prompt,从而让模型能够更好地生成内容。
而另一种更为有效的方案则是,让模型向人对齐。 这也是…

使用ExLlamaV2量化并运行EXL2模型
量化大型语言模型(llm)是减少这些模型大小和加快推理速度的最流行的方法。在这些技术中,GPTQ在gpu上提供了惊人的性能。与非量化模型相比,该方法使用的VRAM几乎减少了3倍,同时提供了相似的精度水平和更快的生成速度。
ExLlamaV2是一个旨在从…

【AI视野·今日NLP 自然语言处理论文速览 第四十一期】Tue, 26 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 26 Sep 2023 Totally 75 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Physics of Language Models: Part 3.1, Knowledge Storage and Extraction Authors Zeyuan Allen Zhu, Yuanz…

【AI视野·今日NLP 自然语言处理论文速览 第四十五期】Mon, 2 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 2 Oct 2023 Totally 44 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Efficient Streaming Language Models with Attention Sinks Authors Guangxuan Xiao, Yuandong Tian, Beidi C…
[算法前沿]--054-大语言模型的学习材料
大语言模型的学习材料
Other Papers
If you’re interested in the field of LLM, you may find the above list of milestone papers helpful to explore its history and state-of-the-art. However, each direction of LLM offers a unique set of insights and contribut…
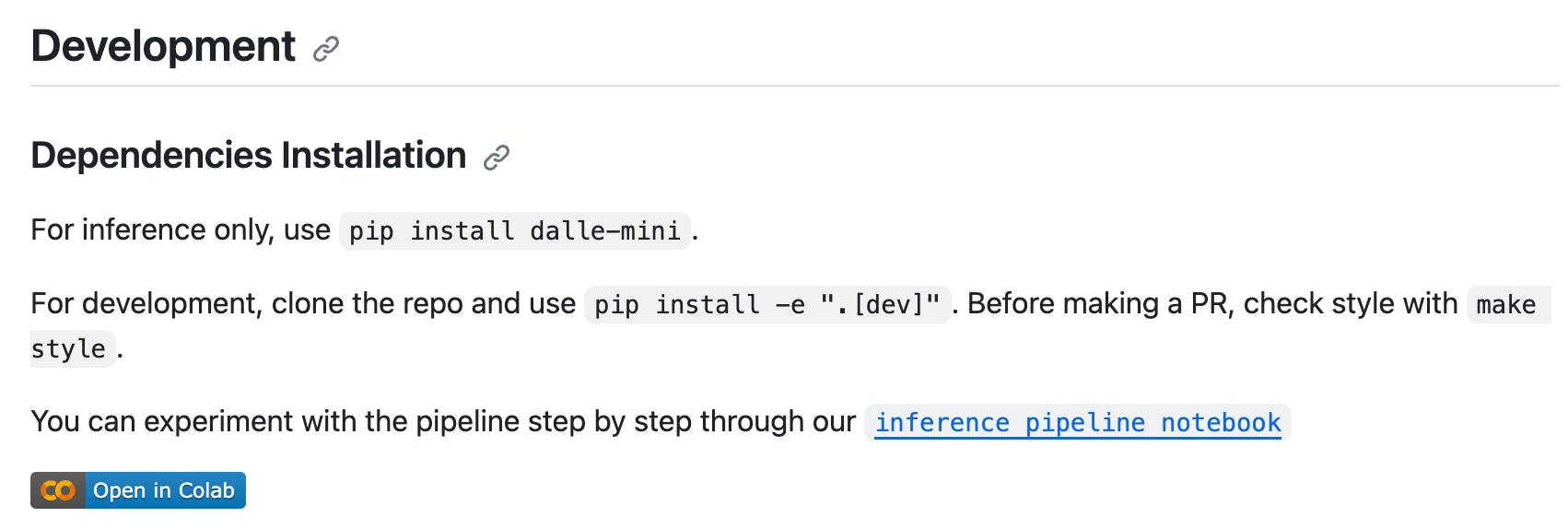
超详细!DALL · E 文生图模型实践指南
最近需要用到 DALLE的推断功能,在现有开源代码基础上发现还有几个问题需要注意,谨以此篇博客记录之。 我用的源码主要是 https://github.com/borisdayma/dalle-mini 仓库中的Inference pipeline.ipynb 文件。 运行环境:Ubuntu服务器
⚠️注意…

【AI视野·今日NLP 自然语言处理论文速览 第六十六期】Tue, 31 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 31 Oct 2023 (showing first 100 of 141 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
The Eval4NLP 2023 Shared Task on Prompting Large Language Models a…
大语言模型LLM微调技术:Prompt Tuning
1 预训练语言模型概述
1.1 预训练语言模型的发展历程 截止23年3月底,语言模型发展走过了三个阶段:
第一阶段 :设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer&#…
【NLP】2024年改变人工智能的前六大NLP语言模型
在快速发展的人工智能领域,自然语言处理已成为研究人员和开发人员关注的焦点。作为这一领域显著进步的证明,近年来出现了几种开创性的语言模型,突破了机器能够理解和生成的界限。在本文中,我们将深入研究大规模语言模型的最新进展…

【AI视野·今日NLP 自然语言处理论文速览 第六十七期】Mon, 1 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 1 Jan 2024 Totally 42 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Principled Gradient-based Markov Chain Monte Carlo for Text Generation Authors Li Du, Afra Amini, Lucas…

【AI视野·今日NLP 自然语言处理论文速览 第四十六期】Tue, 3 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 3 Oct 2023 (showing first 100 of 110 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Its MBR All the Way Down: Modern Generation Techniques Through the …

百题千解计划【CSDN每日一练】LLM大语言模型:必练选择题及解析 | “等差数列”多解法:Python、Java、C语言、C++...
月落乌啼霜满天,江枫渔火对愁眠。 🎯作者主页: 追光者♂🔥 🌸个人简介: 💖[1] 计算机专业硕士研究生💖 🌟[2] 2022年度博客之星人工智能领域TOP4🌟 🏅[3] 阿里云社区特邀专家博主🏅 🏆[4] CSDN-人工智能领域优质创作者🏆 📝[5] …
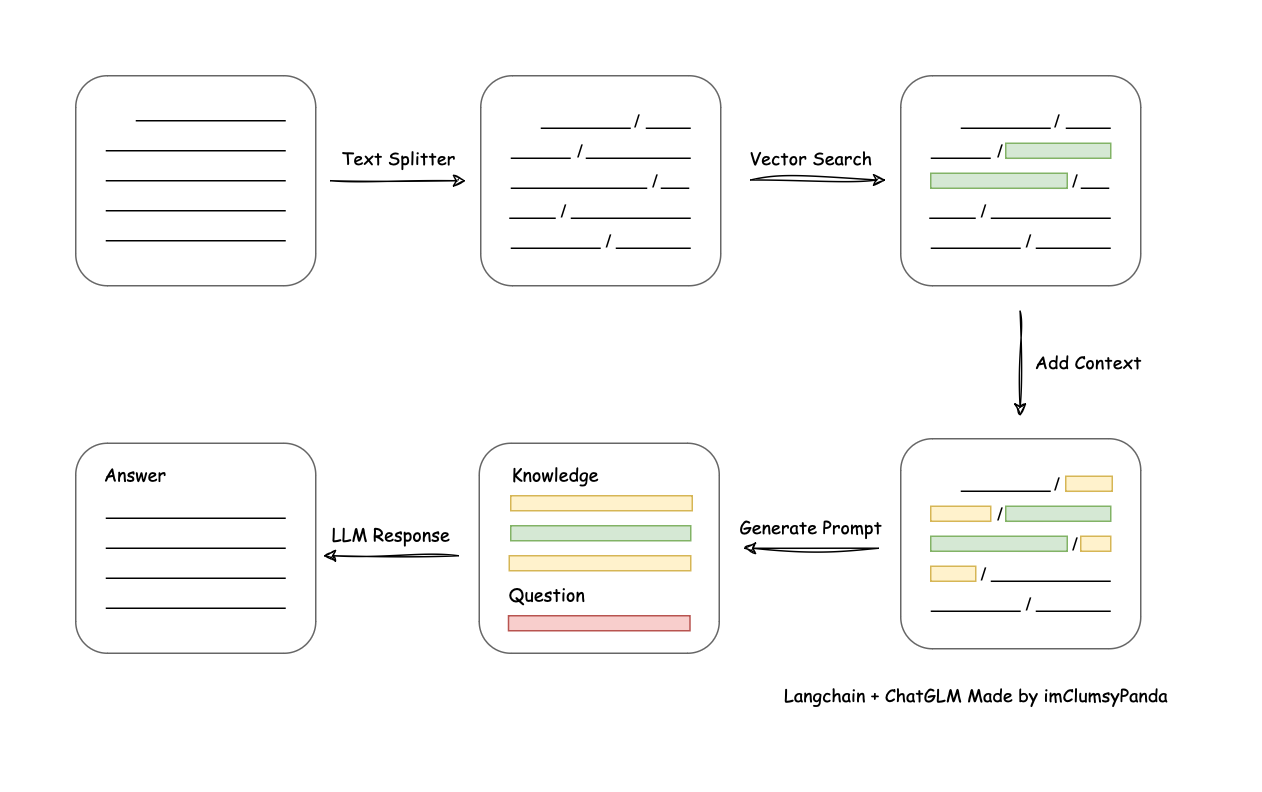
基于Lang-Chain(ChatGLM和ChatChat)知识库大语言模型的部署搭建
环境准备
阿里云个人认证后,可免费试用机器学习平台PAI,可提供适合大语言模型环境搭建的高配置服务器。 点击试用阿里云服务器
试用产品选择:选择交互式建模PAI-DSW
适合哪些场景
文章/知识库/帮助文档等的检索基于现有知识库实现问答… …

什么是大模型微调?微调的分类、方法、和步骤
2023年,大模型成为了重要话题,每个行业都在探索大模型的应用落地,以及其能够如何帮助到企业自身。尽管微软、OpenAI、百度等公司已经在创建并迭代大模型并探索更多的应用,对于大部分企业来说,都没有足够的成本来创建独特的基础模型(Foundation Model):数以百亿计的数据…

大模型自定义算子优化方案学习笔记:CUDA算子定义、算子编译、正反向梯度实现
01算子优化的意义 随着大模型应用的普及以及算力紧缺,下一步对于计算性能的追求一定是技术的核心方向。因为目前大模型的计算逻辑是由一个个独立的算子或者说OP正反向求导实现的,底层往往调用的是GPU提供的CUDA的驱动程序。如果不能对于整个计算过程学习…
Ubuntu 22.04 配置LLM大语言模型环境
本文介绍了清洁安装的Ubuntu Server 22.04 LTS安装NVIDIA显卡驱动、CUDA 12.1、cuDNN的方法及ChatGLM3、百川2、FastChat等大语言模型的部署使用方法。
安装NVIDIA驱动
禁用nouveau
sudo vi /etc/modprobe.d/blacklist.conf尾部追加一行
blacklist nouveau执行并重启系统
…

大规模语言模型人类反馈对齐--RLHF
大规模语言模型在进行监督微调后, 模型具备了遵循指令和多轮对话的能力, 具备了初步与用户进行对话 的能力。然而, 大规模语言模由于庞大的参数量和训练语料, 其复杂性往往难以理解和预测。当这些模型被部署 时, 它们可…
Milvus向量数据库常见用法
创建/断开客户端连接
from pymilvus import connections
# 创建连接
connections.connect(alias"default",userusername,passwordpassword,hostlocalhost,port19530
)# 断开连接
connections.disconnect("default")管理Collection
创建Collection
# 定义…

好莱坞编剧大罢工终于结束;与OpenAI创始人共进早餐;使用DALL-E 3制作绘本分享;生成式AI的基础设施架构 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 好莱坞编剧大罢工终于结束:简单说就是AI妥协了 https://www.wgacontract2023.org/the-campaign/summary-of-the-2023-wga-…
ChatGPT 成为 Nature 年度十大人物,首个非人类实体
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 2023 年即将结束,现在是时候回顾今年的重要科学进展了。12 月 13 日,著名科学期刊《Nature》刚刚发布了 2023 年度的十大人物&…
LoRA:语言模型微调的计算资源优化策略
编者按:随着数据量和计算能力的增加,大模型的参数量也在不断增加,同时进行大模型微调的成本也变得越来越高。全参数微调需要大量的计算资源和时间,且在进行切换下游任务时代价高昂。 本文作者介绍了一种新方法 LoRA,可…
大语言模型无代码构建知识图谱(1)--提示工程准备
2023年3月15日,ChatGPT4.0的横空出世,将人们对大语言模型的关注推到了风口浪尖。由于其在智能问答、翻译以及文本生成等工作任务上的卓越表现,业界一度出现了不再需要发展知识图谱相关技术的观点,知识图谱相关概念严重受挫。无可置…

白话 Transformer 原理-以 BERT 模型为例
白话 Transformer 原理-以 BERT 模型为例
第一部分:引入
1-向量
在数字化时代,数学运算最小单位通常是自然数字,但在 AI 时代,这个最小单元变成了向量,这是数字化时代计算和智能化时代最重要的差别之一。
举个例子:银行在放款前,需要评估一个人的信用度;对于用户而…

【腾讯云云上实验室】向量数据库+LangChain+LLM搭建智慧辅导系统实践
目录 一、搭建智慧辅导系统——向量数据库实践指南1.1、创建向量数据库并新建集合1.2、使用 TKE 快速部署 ChatGLM1.3、部署 LangChain PyPDFVectorDB等组件1.4、配置知识库语料1.5、基于 VectorDB LLM 的智能辅导助手 二、LLM时代的次世代引擎——向量数据库2.1、向量数据库L…
LLM、AGI、多模态AI 篇四:ChatGLM3部署和应用
文章目录 系列简介部署和运行推荐硬件要求部署步骤配置Python环境下载模型文件克隆项目代码安装依赖运行Demo修改demo源代码运行Demo可执行文件应用代码调用Langchain+RAG+ChatGLM3OpenAI API 支持

如何通过 Prompt 优化大模型 Text2SQL 的效果
前言
在上篇文章中「大模型LLM在Text2SQL上的应用实践」介绍了基于SQLDatabaseChain的Text2SQL实践,但对于逻辑复杂的查询在稳定性、可靠性、安全性方面可能无法达到预期,比如输出幻觉、数据安全、用户输入错误等问题。
本文将从以下4个方面探讨通过Pr…
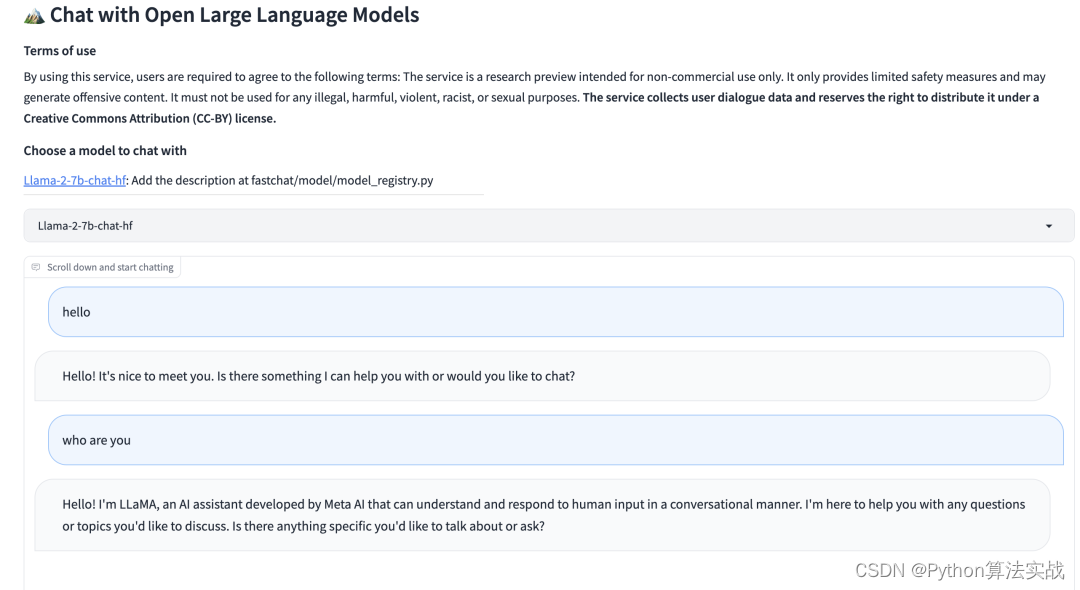
用通俗易懂的方式讲解大模型:使用 FastChat 部署 LLM 的体验太爽了
之前介绍了Langchain-Chatchat 项目的部署,该项目底层改用了 FastChat 来提供 LLM(大语言模型)的 API 服务。
出于好奇又研究了一下 FastChat,发现它的功能很强大,可以用来部署市面上大部分的 LLM 模型,可以将 LLM 部署为带有标准…

千帆Llama 2中文增强技术介绍--SFT,预训练,指令优化
目录
千帆Llama 2中文增强技术介绍
SFT,预训练,指令优化 千帆Llama 2中文增强技术介绍 SFT,预训练,指令优化
书生·浦语大模型实战营第二节课作业
使用 InternLM-Chat-7B 模型生成 300 字的小故事(基础作业1)。 熟悉 hugging face 下载功能,使用 huggingface_hub python 包,下载 InternLM-20B 的 config.json 文件到本地(基础作业2)。
下载过程
进阶…
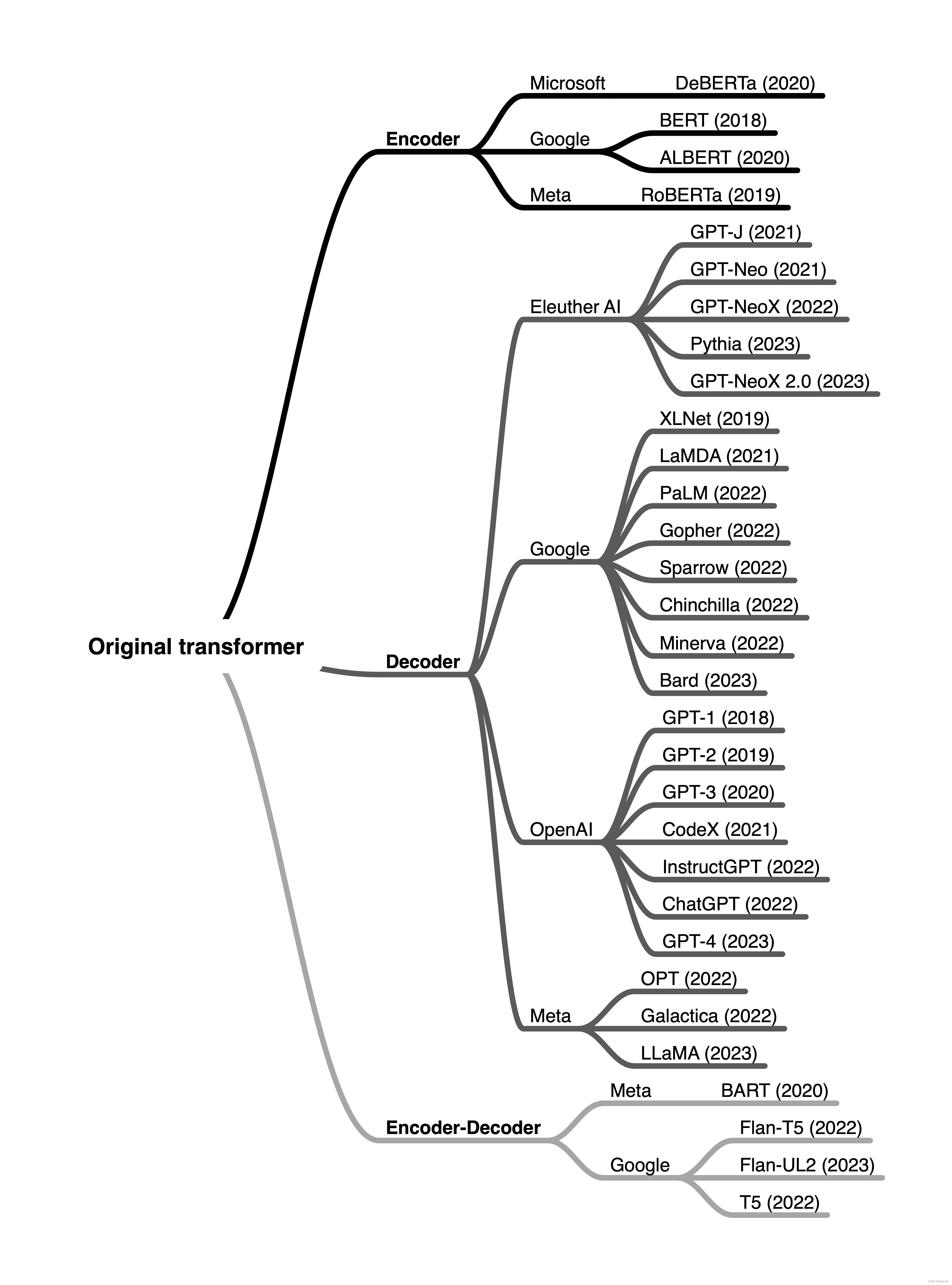
LLM(5) | Encoder 和 Decoder 架构
LLM(5) | Encoder 和 Decoder 架构 文章目录 LLM(5) | Encoder 和 Decoder 架构0. 目的1. 概要2. encoder 和 decoder 风格的 transformer (Encoder- And Decoder-Style Transformers)原始的 transformer (The original transformer)编码器 (Encoders)解码器 (Decoders)编码器和…

Talk|香港科技大学苟耘豪:MoCLE - 指令聚类MoE+通用专家解决多模态大模型任务冲突
本期为TechBeat人工智能社区第571期线上Talk。 北京时间2月8日(周四)20:00,香港科技大学博士生—苟耘豪的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “MoCLE - 指令聚类MoE通用专家解决多模态大模型任务冲突”,系统地介绍…

【AI视野·今日NLP 自然语言处理论文速览 第七十九期】Thu, 18 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 18 Jan 2024 Totally 35 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Deciphering Textual Authenticity: A Generalized Strategy through the Lens of Large Language Semantics …

【AI视野·今日NLP 自然语言处理论文速览 第四十二期】Wed, 27 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 27 Sep 2023 Totally 50 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Attention Satisfies: A Constraint-Satisfaction Lens on Factual Errors of Language Models Authors Mert …

【AI视野·今日NLP 自然语言处理论文速览 第七十一期】Fri, 5 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 5 Jan 2024 Totally 28 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
LLaMA Pro: Progressive LLaMA with Block Expansion Authors Chengyue Wu, Yukang Gan, Yixiao Ge, Zeyu Lu, …
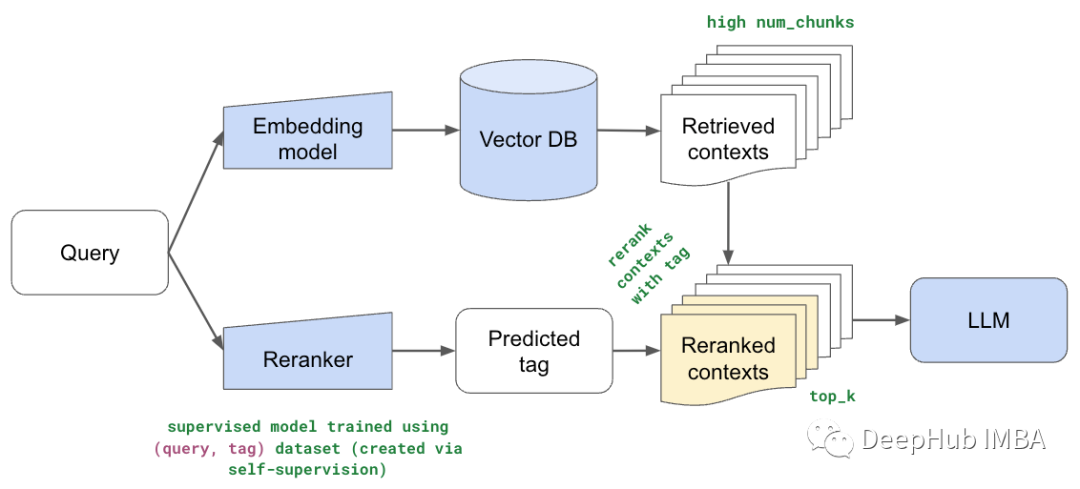
使用Llama index构建多代理 RAG
检索增强生成(RAG)已成为增强大型语言模型(LLM)能力的一种强大技术。通过从知识来源中检索相关信息并将其纳入提示,RAG为LLM提供了有用的上下文,以产生基于事实的输出。
但是现有的单代理RAG系统面临着检索效率低下、高延迟和次优提示的挑战。这些问题在…
LLM、AGI、多模态AI 篇五:基于LoRA微调ChatGLM3
文章目录 系列LLaMA-Factory简介推荐硬件要求环境搭建数据准备指令微调数据集偏好数据集自定义数据集指令监督微调合并 LoRA 权重并导出模型其他(训练全流程)预训练奖励模型训练PPO 强化学习训练DPO 强化学习训练通过一站式网页界面快速上手

【AI视野·今日NLP 自然语言处理论文速览 第六十一期】Tue, 24 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 24 Oct 2023 (showing first 100 of 207 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
LINC: A Neurosymbolic Approach for Logical Reasoning by Combining …

【AI视野·今日NLP 自然语言处理论文速览 第五十六期】Tue, 17 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 17 Oct 2023 (showing first 100 of 135 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Step-by-Step Remediation of Students Mathematical Mistakes Authors…
论文推荐:大型语言模型能自我解释吗?
这篇论文的研究主要贡献是对LLM生成解释的优缺点进行了调查。详细介绍了两种方法,一种是做出预测,然后解释它,另一种是产生解释,然后用它来做出预测。 最近的研究发现,即使LLM是在特定数据上训练的,也不能认…

【自然语言处理】【大模型】LaMDA:用于对话应用程序的语言模型
LaMDA:用于对话应用程序的语言模型 《LaMDA: Language Models for Dialog Applications》 论文地址:https://arxiv.org/abs/2201.08239 相关博客 【自然语言处理】【大模型】LaMDA:用于对话应用程序的语言模型 【自然语言处理】【大模型】Dee…

用开源大语言模型开发的智能对话机器人初版原型验证
用开源大语言模型开发的智能对话机器人初版原型验证 0. 背景1. 初版检证效果展示2. 验证效果总结 0. 背景
同事要想做一个智能对话机器人,特别的需求有有些几点,
通过预置提示词(包括确认事项),让大语言模型用会话式…
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca》翻译与解读
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca》翻译与解读 目录
相关文章
LLMs:《Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca》翻译与解读
LLMs:在单机CPUWindows系统上实现中文…

使用ExLlamaV2在消费级GPU上运行Llama2 70B
Llama 2模型中最大也是最好的模型有700亿个参数。一个fp16参数的大小为2字节。加载Llama 270b需要140 GB内存(700亿* 2字节)。
只要我们的内存够大,我们就可以在CPU上运行上运行Llama 2 70B。但是CPU的推理速度非常的慢,虽然能够运行,速度我…

用通俗易懂的方式讲解:涨知识了,这篇大模型 LangChain 框架与使用示例太棒了
一图胜千言,LangChain已经成为当前 LLM 应用框架的事实标准,本篇文章就来对 LangChain 基本概念以及其具体使用场景做一个整理。 文章目录 用通俗易懂的方式讲解系列技术交流LangChain 是什么LangChain 的主要组件Model I/OLanguage ModelPromptsOutput…
【LLM】人工智能应用构建的十大预训练NLP语言模型
在人工智能领域,自然语言处理(NLP)被广泛认为是阅读、破译、理解和理解人类语言的最重要工具。有了NLP,机器可以令人印象深刻地模仿人类的智力和能力,从文本预测到情感分析再到语音识别。
什么是自然语言处理…

周鸿祎为360智脑招贤纳士;LLM时代的选择指南;Kaggle大语言模型实战;一文带你逛遍LLM全世界 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 思否「齐聚码力」黑客马拉松,用技术代码让生活变得更美好 主页:https://pages.segmentfault.com/google-hacka…
DL之RNN之BiLSTM:基于IMDb电影评论数据集利用BiLSTM算法实现对电影评论进行情感分析二分类+模型训练过程可视化+模型推理实战代码之详细攻略
DL之RNN之BiLSTM:基于IMDb电影评论数据集利用BiLSTM算法实现对电影评论进行情感分析二分类+模型训练过程可视化+模型推理实战代码之详细攻略 目录

AI小百科 - 什么是大语言模型(Large Language Model)?
我是一个特殊的机器人助手,名字叫做LLM(Large Language Model)。想象一下,你知道电脑是怎么帮助人们做各种事情的吧?LLM就是一种非常聪明的电脑程序,它被训练得非常聪明,可以回答各种各样的问题…

【AI视野·今日NLP 自然语言处理论文速览 第五十九期】Fri, 20 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 20 Oct 2023 Totally 74 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
AutoMix: Automatically Mixing Language Models Authors Aman Madaan, Pranjal Aggarwal, Ankit Anand, Sriv…
ICLR 2024 高分论文 | Step-Back Prompting 使大语言模型通过抽象进行推理
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2024 高分论文:《Step-Back Prompting Enables Reasoning Via Abstraction in Large Language Models》
论文地址:https://openreview.net/forum?id=3bq3jsvcQ1
…
【ChatGLM2-6B】P-Tuning训练微调
机器配置
阿里云GPU规格ecs.gn6i-c4g1.xlargeNVIDIA T4显卡*1GPU显存16G*1
准备训练数据
进入/ChatGLM-6B/ptuningmkdir AdvertiseGencd AdvertiseGen上传 dev.json 和 train.json内容都是
{"content": "你是谁", "summary": "你好&…

使用Accelerate库在多GPU上进行LLM推理
大型语言模型(llm)已经彻底改变了自然语言处理领域。随着这些模型在规模和复杂性上的增长,推理的计算需求也显著增加。为了应对这一挑战利用多个gpu变得至关重要。 所以本文将在多个gpu上并行执行推理,主要包括:Accelerate库介绍,…
【LLM】自主GPT-4:从ChatGPT到AutoGPT、AgentGPT、BabyAGI、HuggingGPT等
LangChain和LlamaIndex集成趋势后,GPT-4的新兴任务自动化和人工智能代理 ChatGPT和LLM技术的出现是革命性的。这些最先进的语言模型席卷了世界,激励开发人员、爱好者和组织探索集成和构建这些尖端模型的创新方法。因此,LangChain和LlamaIndex…
提示(Prompt)工程中提示词的开发优化基础概念学习总结
本文对学习过程进行总结,仅对基本思路进行说明,结果在不同的模型上会有差异。
提示与提示工程
提示:指的是向大语言模型输入的特定短语或文本,用于引导模型产生特定的输出,以便模型能够生成符合用户需求的回应。 提示…

【书生·浦语大模型实战营】学习笔记1
大模型成为发展通用人工智能的重要途经 专用模型:针对特定任务,一个模型解决一个问题 通用大模型:一个模型应对多种任务、多种模态 书生浦语大模型系列 上海人工智能实验室 轻量级、中量级、重量级 7B 和 123B的轻量级和中量级大模型都是开源…

微软 CMU - Tag-LLM:将通用大语言模型改用于专业领域
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 论文地址:https://arxiv.org/abs/2402.05140
Github 地址:https://github.com/sjunhongshen/Tag-LLM
大语言模型(…
大语言模型初学者指南 (2023)
大语言模型 (LLM) 是深度学习的一个子集,它正在彻底改变自然语言处理领域。它们是功能强大的通用语言模型,可以针对大量数据进行预训练,然后针对特定任务进行微调。这使得LLM能够拥有大量的一般数据。如果一个人想将LLM用于特定目的ÿ…

【LLM】浅谈 StreamingLLM中的attention sink和sink token
前言
Softmax函数 SoftMax ( x ) i e x i e x 1 ∑ j 2 N e x j , x 1 ≫ x j , j ∈ 2 , … , N \text{SoftMax}(x)_i \frac{e^{x_i}}{e^{x_1} \sum_{j2}^{N} e^{x_j}}, \quad x_1 \gg x_j, j \in 2, \dots, N SoftMax(x)iex1∑j2Nexjexi,x1≫xj,j∈2,……
ChatGLM3-6B:新一代开源双语对话语言模型,流畅对话与低部署门槛再升级
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…

【AI视野·今日NLP 自然语言处理论文速览 四十九期】Fri, 6 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 6 Oct 2023 Totally 44 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
MathCoder: Seamless Code Integration in LLMs for Enhanced Mathematical Reasoning Authors Ke Wang, Houxi…
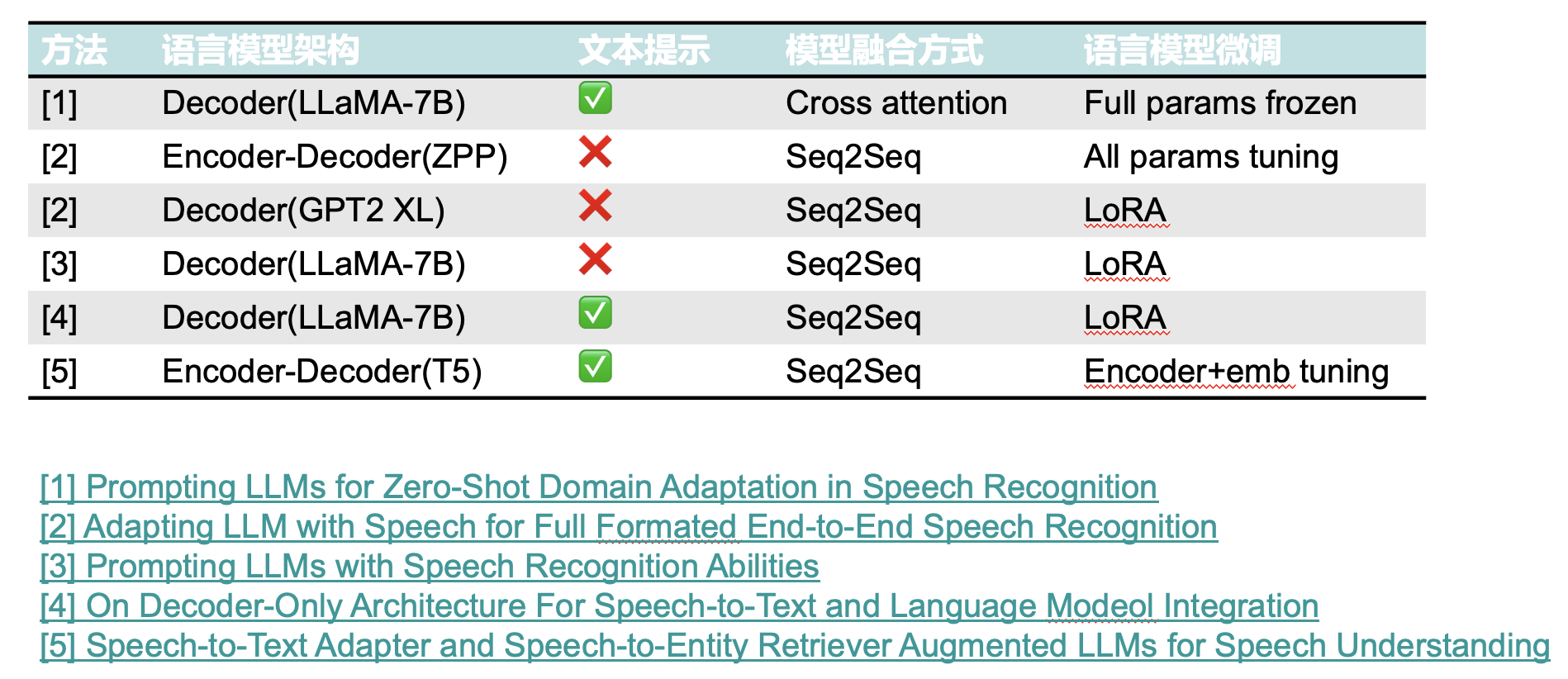
ASR(自动语音识别)任务中的LLM(大语言模型)
一、LLM大语言模型的特点 二、大语言模型在ASR任务中的应用
浅度融合
浅层融合指的是LLM本身并没有和音频信息进行直接计算。其仅对ASR模型输出的文本结果进行重打分或者质量评估。
深度融合
LLM与ASR模型进行深度结合,统一语音和文本的编码空间或者直接利用ASR…
LlamaIndex中的CustomLLM(在线加载模型)
一.使用 Flask 将模型封装为 REST 接口 主要是将 complete()和 stream_complete()方法封装为 REST 接口,如下所示:
from flask import Flask, request, jsonify
from transformers import AutoTokenizer, AutoModelForCausalLM
app Flask(__name__)cla…
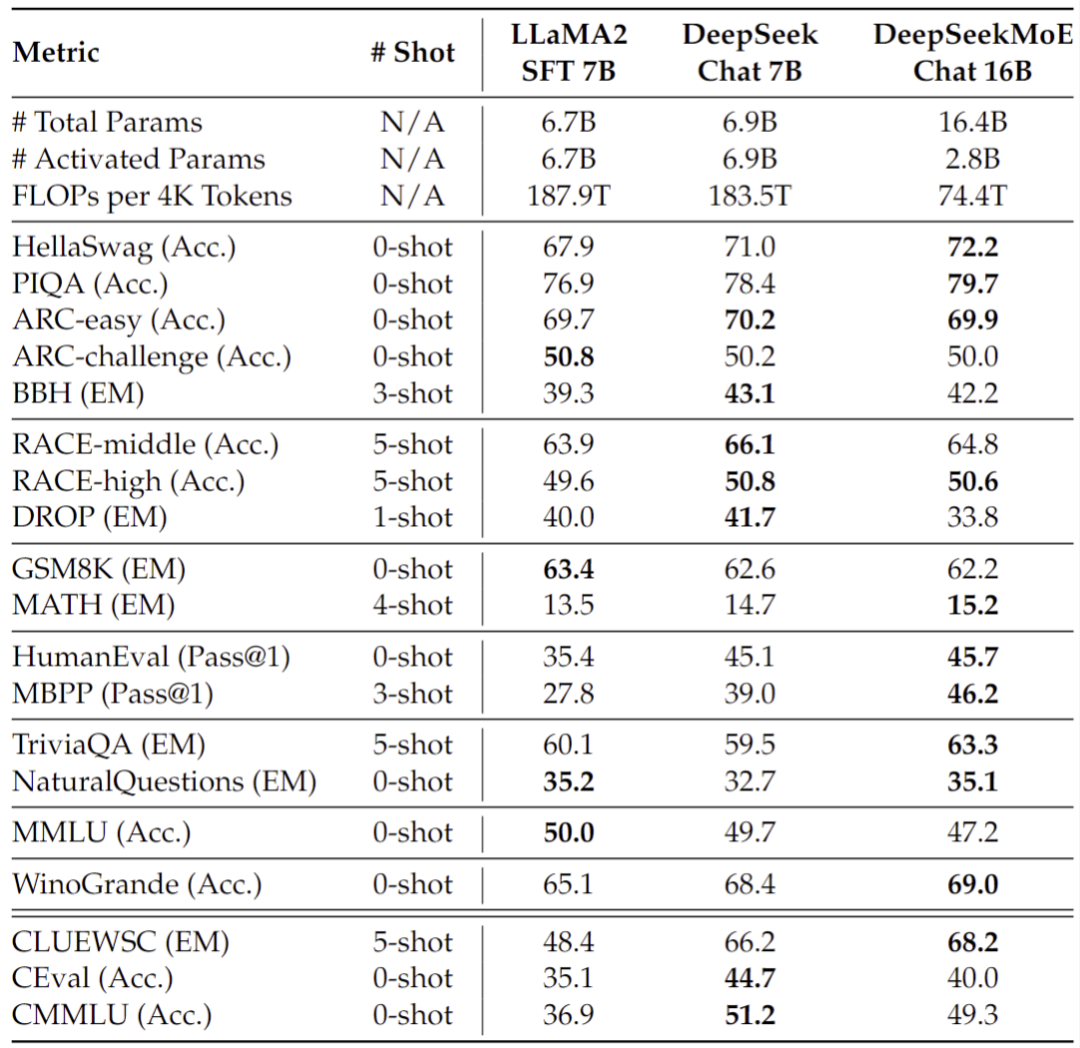
深度求索开源国内首个 MoE 大模型 | DeepSeekMoE:在专家混合语言模型中实现终极专家专业化
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 在大语言模型时代,混合专家模型(MoE)是一种很有前途的架构,用于在扩展模型参数时管理计算成本。然而&a…

大模型 LLM RAG在 Text2SQL 上的应用实践
1. 前言
在上篇文章中「LLM Agent在Text2SQL应用上的实践」介绍了基于AI Agent来优化LLM的Text2SQL转换效果的实践,除此之外我们还可以使用RAG(Retrieval-Augmented Generation)来优化大模型应用的效果。
本文将从以下4个方面探讨通过RAG来…

将AI融入CG特效工作流;对谈Dify创始人张路宇;关于Llama 2的一切资源;普林斯顿LLM高阶课程;LLM当前的10大挑战 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 将AI融入CG特效工作流,体验极致的效率提升 BV1pP411r7HY 这是 B站UP主 特效小哥studio 和 拓星研究所 联合投稿的一个AI特…

使用CLIP和LLM构建多模态RAG系统
在本文中我们将探讨使用开源大型语言多模态模型(Large Language Multi-Modal)构建检索增强生成(RAG)系统。本文的重点是在不依赖LangChain或LLlama index的情况下实现这一目标,这样可以避免更多的框架依赖。
什么是RAG
在人工智能领域,检索增强生成(re…

如何避免LLM的“幻觉”(Hallucination)
生成式大语言模型(LLM)可以针对各种用户的 prompt 生成高度流畅的回复。然而,大模型倾向于产生幻觉或做出非事实陈述,这可能会损害用户的信任。
大语言模型的长而详细的输出看起来很有说服力,但是这些输出很有可能是虚…
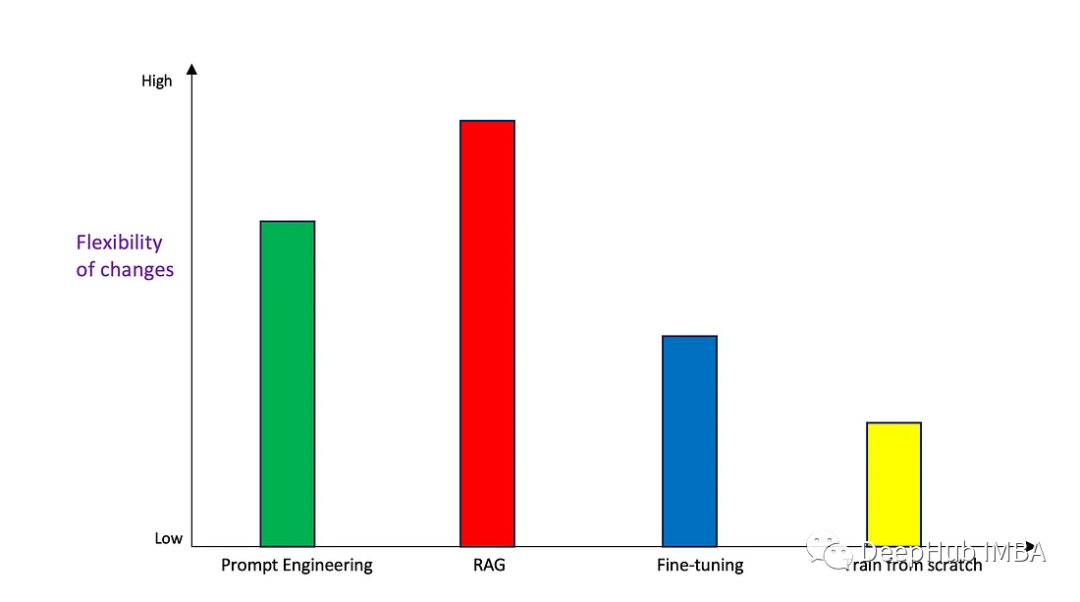
Prompt、RAG、微调还是重新训练?如何选择正确的生成式AI的使用方法
生成式人工智能正在快速发展,许多人正在尝试使用这项技术来解决他们的业务问题。一般情况下有4种常见的使用方法:
Prompt EngineeringRetrieval Augmented Generation (RAG 检索增强生成)微调从头开始训练基础模型(FM)
本文将试图根据一些常见的可量化…

使用LoRA对大语言模型LLaMA做Fine-tune
使用LoRA对大语言模型LLaMA做Fine-tune 前言下载配置环境模型的训练 Fine-tune模型的使用 Inference参考 前言 目前有大量对LLM(大语言模型)做Fine-tune的方式,不过需要消耗的资源非常高,例如 Stanford Alpaca: 对LLaMA-7B做Fine-…
论文笔记 | ICLR 2023 WikiWhy:回答和解释因果问题
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2023 | Accept: notable-top-5%:《WikiWhy: Answering and Explaining Cause-and-Effect Questions》
一段话总结:WikiWhy 是一个新的 QA 数据集,围绕一个新的任务…
大语言模型无代码构建知识图谱概述
2023年3月15日,ChatGPT4.0的横空出世,将人们对大语言模型的关注推到了风口浪尖。由于其在智能问答、翻译以及文本生成等工作任务上的卓越表现,业界一度出现了不再需要发展知识图谱相关技术的观点,知识图谱相关概念严重受挫。无可置…
AI小百科 - 什么是词向量?
如何表示一个单词的意义?对人来说,一般用解释法,用一段话来解释词的含义。如“太阳”在新华字典中的释义是“太阳系的中心天体。银河系的一颗普通恒星。”然而,这样的解释计算机是听不懂的,必须用更简洁的方式来对词义…
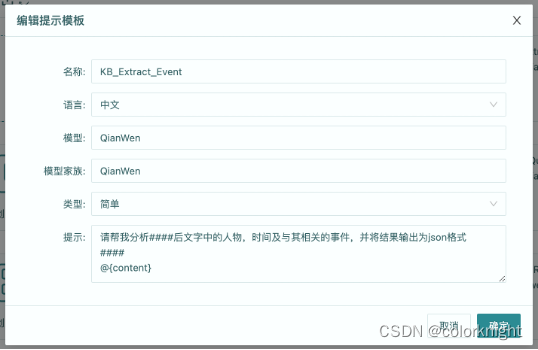
大语言模型无代码构建知识图谱(2)--环境准备
软件环境
需已安装MySQL数据库。需已安装HuggingFists系统,该系统将提供无代码的可视化数据开发环境。通过该系统利用大语言模型辅助知识图谱的构建。HuggingFists系统的安装可参考《HuggingFists-低代码玩转LLM RAG-准备篇》
流程环境
数据文件
进入HuggingFis…
【AI实战】大语言模型(LLM)有多强?还需要做传统NLP任务吗(分词、词性标注、NER、情感分类、知识图谱、多伦对话管理等)
【AI实战】大语言模型(LLM)有多强?还需要做传统NLP任务吗(分词、词性标注、NER、情感分类、多伦对话管理等) 大语言模型大语言模型有多强?分词词性标注NER情感分类多伦对话管理知识图谱 总结 大语言模型
大…
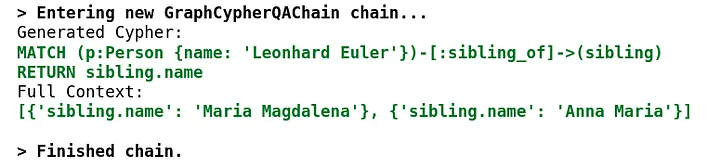
使用 Neo4j 和 LangChain 集成非结构化知识图增强 QA
目前基于大模型的信息检索有两种方法,一种是基于微调的方法,一种是基于 RAG 的方法。
信息检索和知识提取是一个不断发展的领域,随着大型语言模型(LLM)和知识图的出现,这一领域发生了显着的变化࿰…

【AI视野·今日NLP 自然语言处理论文速览 第五十五期】Mon, 16 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 16 Oct 2023 Totally 53 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
PromptRE: Weakly-Supervised Document-Level Relation Extraction via Prompting-Based Data Programming Au…

【AI视野·今日NLP 自然语言处理论文速览 第七十二期】Mon, 8 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 8 Jan 2024 Totally 17 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism Authors DeepSeek AI Xiao Bi, Deli Ch…

【AI视野·今日NLP 自然语言处理论文速览 第五十一期】Tue, 10 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 10 Oct 2023 (showing first 100 of 172 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Few-Shot Spoken Language Understanding via Joint Speech-Text Model…

【AI视野·今日NLP 自然语言处理论文速览 第六十九期】Wed, 3 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 3 Jan 2024 Totally 24 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction Authors Zaratiana Ur…
【LangChain】与文档聊天:将OpenAI与LangChain集成的终极指南
欢迎来到人工智能的迷人世界,在那里,人与机器之间的通信越来越模糊。在这篇博客文章中,我们将探索人工智能驱动交互的一个令人兴奋的新前沿:与您的文本文档聊天!借助OpenAI模型和创新的LangChain框架的强大组合&#x…

11月推荐阅读的12篇大语言模型相关论文
现在已经是12月了,距离2024年只有一个月了,本文总结了11月的一些比较不错的大语言模型相关论文
System 2 Attention (is something you might need too).
https://arxiv.org/abs/2311.11829
一种称为S2A的新注意力方法被开发出来,解决llm…
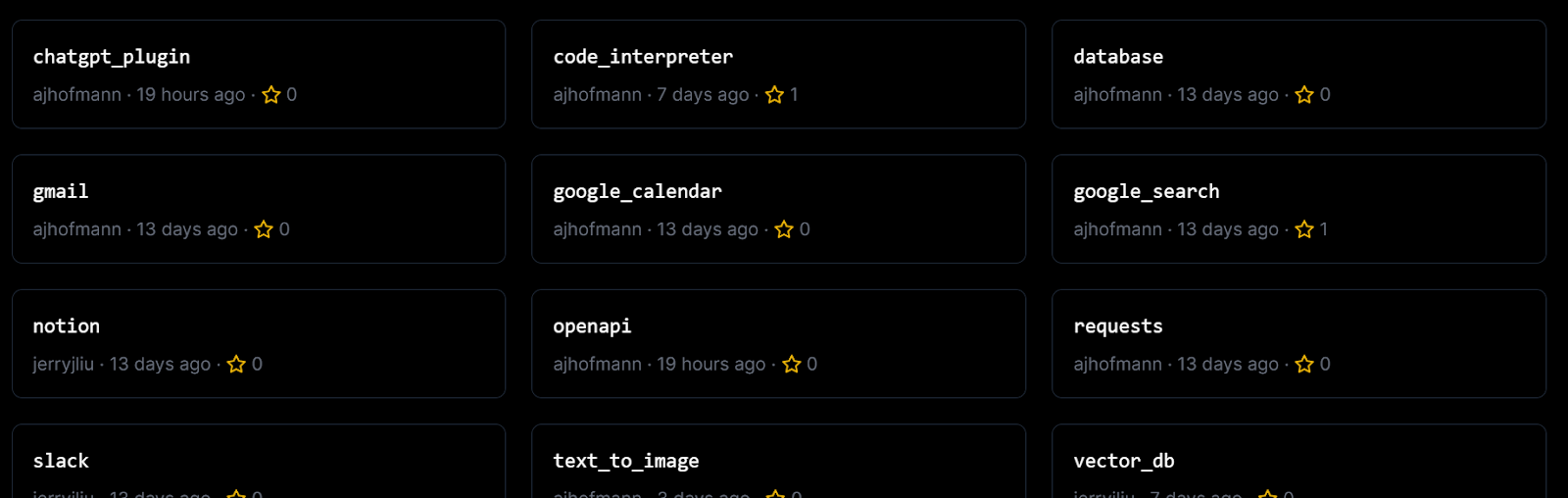
LlamaIndex:将个人数据添加到LLM
推荐:使用 NSDT场景编辑器 快速搭建3D应用场景 LlamaIndex是基于大型语言模型(LLM)的应用程序的数据框架。像 GPT-4 这样的 LLM 是在大量公共数据集上预先训练的,允许开箱即用的令人难以置信的自然语言处理能力。但是,…
马斯克发布大模型Grok;主流AI创意生成工具图谱;Runway视频大赛获奖作品解析;DALL-E 3图像混合操作;42章经播客推荐 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 👀 马斯克「xAI」发布首个AI大模型「Grok」 https://grok.x.ai 11月5日,马斯克旗下人工智能公司 xAI 发布了首款 AI 聊天产品…
如何使用ChatGPT,而不是生成默认风格的八股文
现在我每天都使用ChatGPT来执行多项任务,包括但不限于内容创建。无论是编写文本还是与我讨论我的业务目标,ChatGPT总是会时不时的用到。 但与所有强大的工具一样,ChatGPT 和类似的大型语言模型 (LLM) 也有其局限性。在我从事人工智能工作的过…

全套解决方案:基于pytorch、transformers的中文NLP训练框架,支持大模型训练和文本生成,快速上手,海量训练数据!
全套解决方案:基于pytorch、transformers的中文NLP训练框架,支持大模型训练和文本生成,快速上手,海量训练数据!
1.简介
目标:基于pytorch、transformers做中文领域的nlp开箱即用的训练框架,提…
LLM大语言模型(典型ChatGPT)入门指南
文章目录 一、基础概念学习篇1.1 langchain视频学习笔记1.2 Finetune LLM视频学习笔记 二、实践篇2.1 预先下载模型:2.2 LangChain2.3 Colab demo2.3 text-generation-webui 三、国内项目实践langchain-chatchat 一、基础概念学习篇
1.1 langchain视频学习笔记 lan…
【LLM】2023年大型语言模型训练
2022年底,大型语言模型(LLM)在互联网上掀起了风暴,OpenAI的ChatGPT在推出5天后就达到了100万用户。ChatGPT的功能和广泛的应用程序可以被认可为GPT-3语言模型所具有的1750亿个参数
尽管使用像ChatGPT这样的最终产品语言模型很容易…
9月人工智能论文和项目推荐
因为LLM的火爆,所以最近的论文都是和LLM相关的
论文
1、LongLoRA
LoRA是人工智能中有效扩展预训练语言模型(llm)上下文大小的一种方法。LongLoRA通过在训练期间利用稀疏的局部注意力和在推理期间利用密集的全局注意力,允许进行经济有效的微调并保持性…
论文笔记 | ICLR 2023 ReAct:通过整合推理和行动来增强语言模型
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2023 | Accept: notable-top-5%:《ReAct: Synergizing Reasoning and Acting in Language Models》
一句话总结:ReAct 方法在问答任务中通过提示大语言模型生成与任…
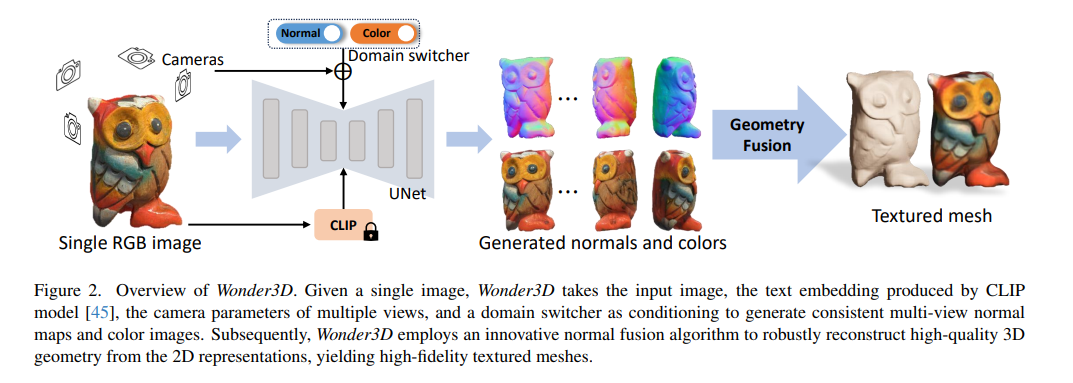
【AI视野·今日CV 计算机视觉论文速览 第274期】Tue, 24 Oct 2023
AI视野今日CS.CV 计算机视觉论文速览 Tue, 24 Oct 2023 Totally 138 papers 👉上期速览✈更多精彩请移步主页 Interesting:
📚Wonder3D, 基于交叉扩散模型的单图像三维形状生成。(from 香港大学) website:https://www.xxlong.site/Wonder3D/ Daily Co…
这次轮到微软炸场了;5000+AI工具调研报告 (500万字);狂打一星开喷AI聊天机器人;CMU LLM课程;AI创业的方向与时机 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🉑 Microsoft Ignite 2023 技术大会:微软的年度炸场时刻,而且连炸四天 https://ignite.microsoft.com OpenAI 开发…

【AI视野·今日NLP 自然语言处理论文速览 第四十八期】Thu, 5 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 5 Oct 2023 Totally 50 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Retrieval meets Long Context Large Language Models Authors Peng Xu, Wei Ping, Xianchao Wu, Lawrence McA…

Talk | 纽约州立宾汉姆顿大学博士生丁琰:开放环境中机器人的任务与动作规划
本期为TechBeat人工智能社区第541期线上Talk。 北京时间10月26日(周四)20:00,纽约州立宾汉姆顿大学博士生—丁琰的Talk已准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “开放环境中机器人的任务与动作规划”࿰…
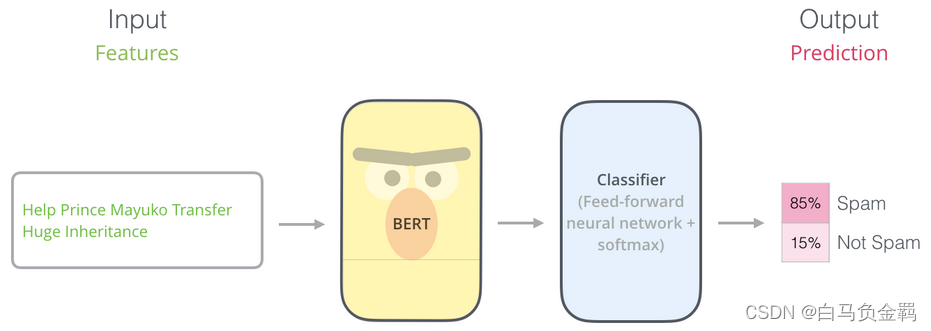
BERT(从理论到实践): Bidirectional Encoder Representations from Transformers【3】
这是本系列文章中的第3弹,请确保你已经读过并了解之前文章所讲的内容,因为对于已经解释过的概念或API,本文不会再赘述。
本文要利用BERT实现一个“垃圾邮件分类”的任务,这也是NLP中一个很常见的任务:Text Classification。我们的实验环境仍然是Python3+Tensorflow/Keras…
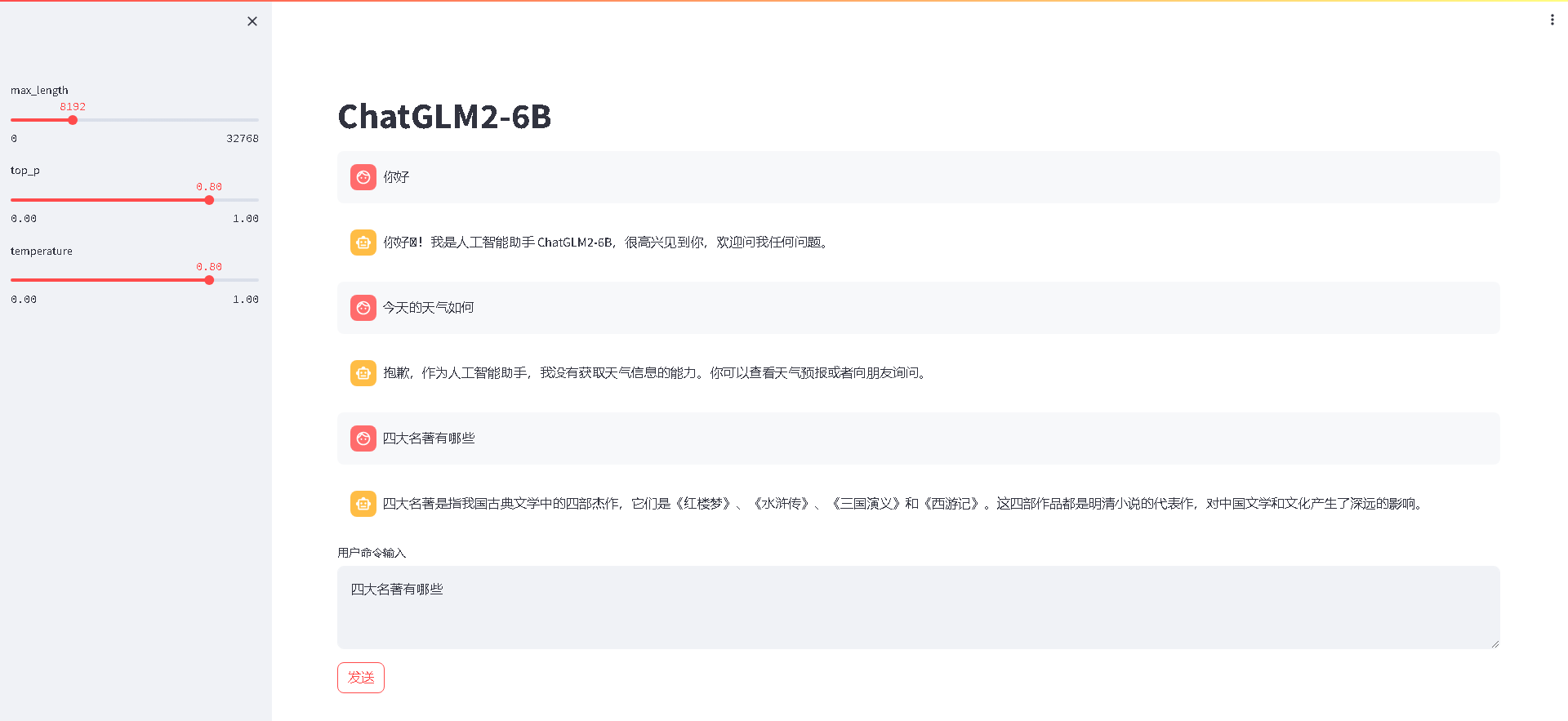
【ChatGLM2-6B】在只有CPU的Linux服务器上进行部署
简介
ChatGLM2-6B 是清华大学开源的一款支持中英双语的对话语言模型。经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,具有62 亿参数的 ChatGLM2-6B 已经能生成相当符合人类偏好的回答。结合模型量化技术,用户可以在消费级的显卡上进行本地部署&…
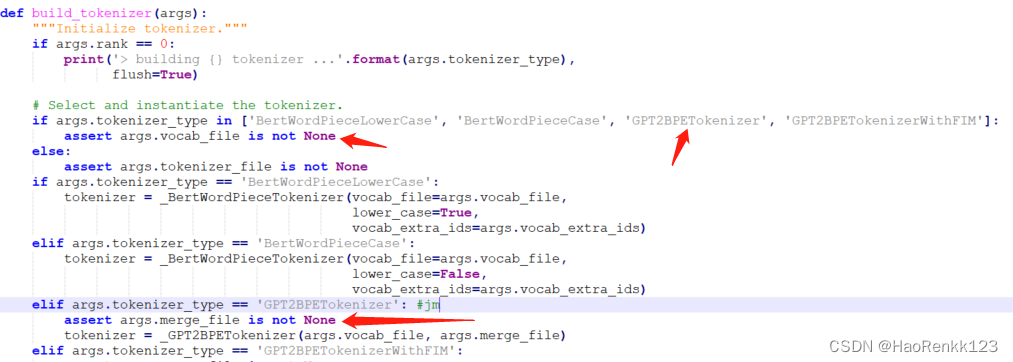
MegatronLM源码阅读-数据预处理
数据处理入口:
python tools/preprocess_data.py \--input content.jsonl \--output-prefix wudaocorpus_01 \--vocab ../starcoder/vocab.json \--dataset-impl mmap \--tokenizer-type GPT2BPETokenizer \--merge-file ../starcoder/merges.txt \--json-keys content \--wo…

本地部署GPT的实战方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
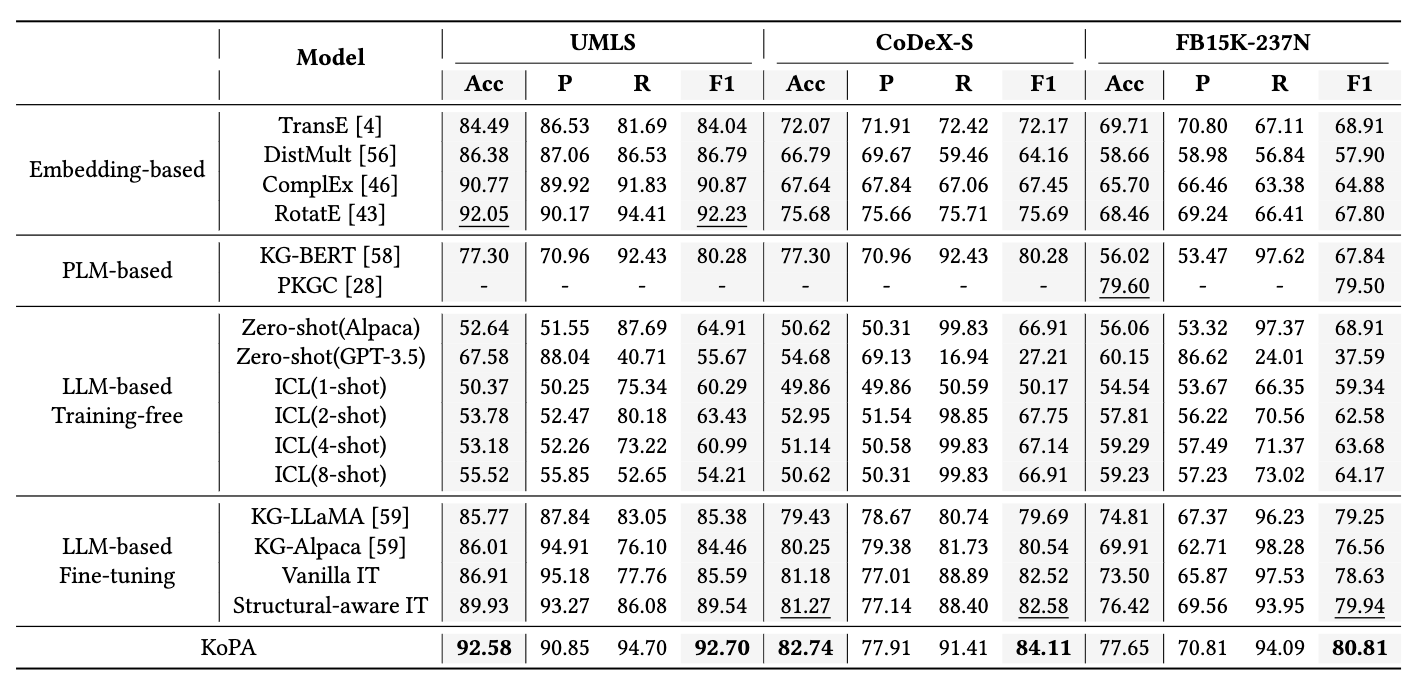
如何让大模型更好地完成知识图谱推理?
论文标题: Making Large Language Models Perform Better in Knowledge Graph Completion 论文链接: https://arxiv.org/abs/2310.06671 代码链接:GitHub - zjukg/KoPA: [Paper][Preprint 2023] Making Large Language Models Perform Be…
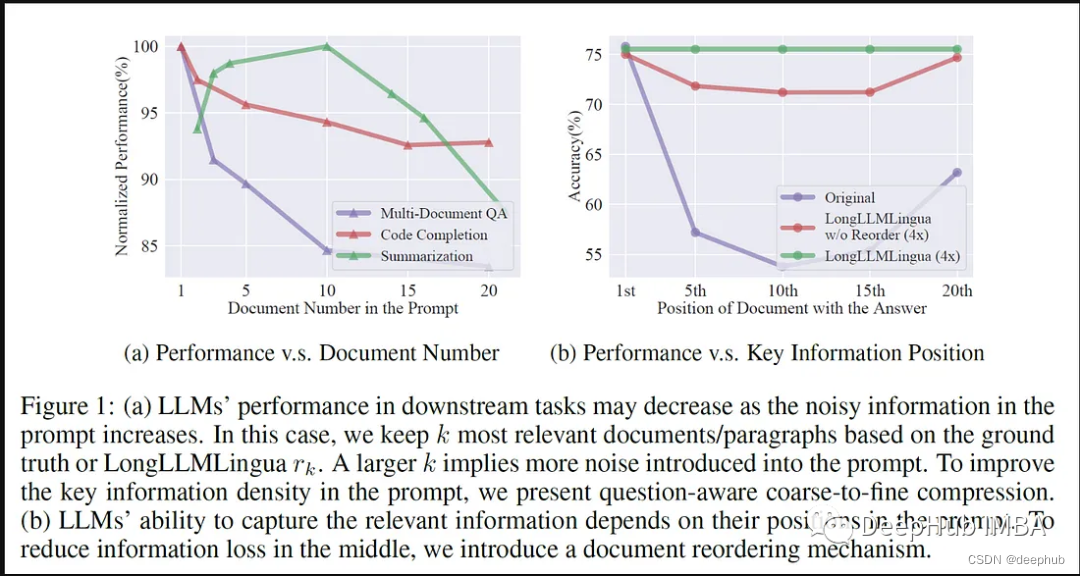
LLMLingua:集成LlamaIndex,对提示进行压缩,提供大语言模型的高效推理
大型语言模型(llm)的出现刺激了多个领域的创新。但是在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。这些冗长的提示需要大量的资源来进行推理,因此需要高效的解决方案,本文将介绍LLM…
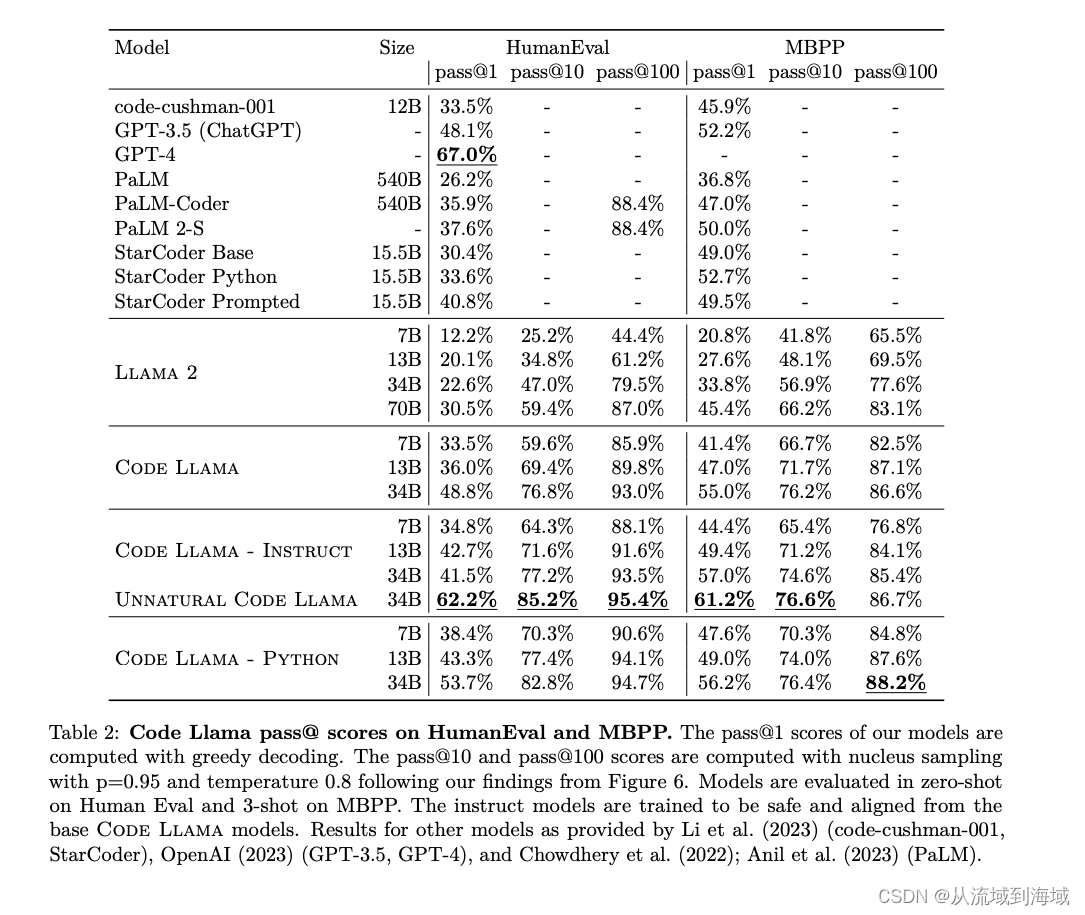
最强英文开源模型Llama2架构与技术细节探秘
prerequisite: 最强英文开源模型LLaMA架构探秘,从原理到源码 Llama2 Meta AI于2023年7月19日宣布开源LLaMA模型的二代版本Llama2,并在原来基础上允许免费用于研究和商用。
作为LLaMA的延续和升级,Llama2的训练数据扩充了40%,达到…
超越界限:大模型应用领域扩展,探索文本分类、文本匹配、信息抽取和性格测试等多领域应用
超越界限:大模型应用领域扩展,探索文本分类、文本匹配、信息抽取和性格测试等多领域应用
随着 ChatGPT 和 GPT-4 等强大生成模型出现,自然语言处理任务方式正在逐步发生改变。鉴于大模型强大的任务处理能力,未来我们或将不再为每…
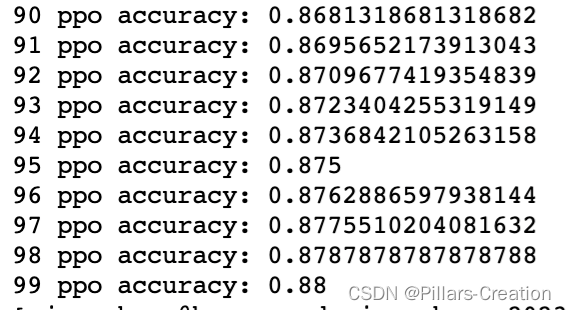
大语言模型-RLHF(七)-PPO实践(Proximal Policy Optimization)原理实现代码逐行注释
从open AI 的论文可以看到,大语言模型的优化,分下面三个步骤,SFT,RM,PPO,我们跟随大神的步伐,来学习一下这三个步骤和代码实现,本章介绍PPO实践。
生活中,我们经常会遇到…
大语言模型LangChain+ChatGLM3-6B的本地知识库与行业知识库价值体现
文章目录 大语言模型LangChainChatGLM3-6B的本地知识库与行业知识库价值体现引言本地知识库与行业知识库的重要性LangChain在知识库管理中的应用应用场景分析展望 大语言模型LangChainChatGLM3-6B的本地知识库与行业知识库价值体现
引言
在人工智能的浪潮中,大型语…

【通览一百个大模型】Baize(UCSD)
【通览一百个大模型】Baize(UCSD) 作者:王嘉宁,本文章内容为原创,仓库链接:https://github.com/wjn1996/LLMs-NLP-Algo 订阅专栏【大模型&NLP&算法】可获得博主多年积累的全部NLP、大模型和算法干货…

【AI视野·今日NLP 自然语言处理论文速览 第七十期】Thu, 4 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 4 Jan 2024 Totally 29 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Multilingual Instruction Tuning With Just a Pinch of Multilinguality Authors Uri Shaham, Jonathan Herzi…

【AI视野·今日NLP 自然语言处理论文速览 第七十三期】Tue, 9 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Tue, 9 Jan 2024 Totally 80 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
FFSplit: Split Feed-Forward Network For Optimizing Accuracy-Efficiency Trade-off in Language Model Infe…

【AI视野·今日NLP 自然语言处理论文速览 第五十七期】Wed, 18 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 18 Oct 2023 Totally 82 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
VeRA: Vector-based Random Matrix Adaptation Authors Dawid Jan Kopiczko, Tijmen Blankevoort, Yuki Marku…

【AI视野·今日NLP 自然语言处理论文速览 第五十八期】Thu, 19 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 19 Oct 2023 Totally 74 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Understanding Retrieval Augmentation for Long-Form Question Answering Authors Hung Ting Chen, Fangyuan…
“超级AI助手:全新提升!中文NLP训练框架,快速上手,海量训练数据,ChatGLM-v2、中文Bloom、Dolly_v2_3b助您实现更智能的应用!”
“超级AI助手:全新提升!中文NLP训练框架,快速上手,海量训练数据,ChatGLM-v2、中文Bloom、Dolly_v2_3b助您实现更智能的应用!”
1.简介
目标:基于pytorch、transformers做中文领域的nlp开箱即用…

思维链(CoT)提出者 Jason Wei:关于大语言模型的六个直觉
文章目录 一、前言二、主要内容三、总结 🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 Jason Wei 的主页:https://www.jasonwei.net/
Jason Wei,一位于 2020 年从达特茅斯学院毕业的杰出青年,随后加盟了…

时隔一年的测评:gpt3.5发展到什么程度了?
名人说:一花独放不是春,百花齐放花满园。——《增广贤文》 作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、简要介绍1、chatgpt是什么?2、主要特点3、工作原理4、应用限制5、使…

大模型分布式并行技术--分布式系统
近年来, 大多数出现在顶级人工智能会议上的模型都是在多个 GPU 上训练的, 特别是随着基于 Transformer 的语言模型的提出。当研究人员和工程师开发人工智能模型时, 分布式训练无疑是一种常见的做法。传统的单 机单卡模式已经无法满足超大模型…

小白学大模型LLMs:文本分词方法
本文介绍了各种类型的分词(tokenization),用于将单词拆分为一个或多个标记(token),因为单词和分词之间存在一对多的关系。
什么是预分词(Pre-tokenization)
预分词是在处理基于文本…
完整时间线!李开复Yi大模型套壳争议;第二届AI故事大赛;AI算命GPTs;LLM应用全栈开发笔记;GPT-5提上日程 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 👀 李开复「零一万物」大模型陷套壳争议,事件时间线完整梳理 https://huggingface.co/01-ai/Yi-34B/discussions/11#65531458…
Microsoft的PromptBench可以做啥?
目录
PromptBench简介
PromptBench的快速模型性能评估
PromptBench数据集介绍
PromptBench模型介绍
PromptBench模型加载遇到的问题
第一次在M1 Mac上加载模型
vicuna和llama系列模型
PromptBench各个模型加载情况总结
PromptBench的Prompt快速工程
chain of thought…

【论文精读】LLaMA1
摘要 以往的LLM(Large Languages Models)研究都遵从一个假设,即更多的参数将导致更好的性能。但也发现,给定计算预算限制后,最佳性能的模型不是参数最大的,而是数据更多的。对于实际场景,首选的…
【ChatGLM2-6B】小白入门及Docker下部署
【ChatGLM2-6B】小白入门及Docker下部署 一、简介1、ChatGLM2是什么2、组成部分3、相关地址 二、基于Docker安装部署1、前提2、CentOS7安装NVIDIA显卡驱动1)查看服务器版本及显卡信息2)相关依赖安装3)显卡驱动安装 2、 CentOS7安装NVIDIA-Doc…
使用TensorRT-LLM进行高性能推理
LLM的火爆之后,英伟达(NVIDIA)也发布了其相关的推理加速引擎TensorRT-LLM。TensorRT是nvidia家的一款高性能深度学习推理SDK。此SDK包含深度学习推理优化器和运行环境,可为深度学习推理应用提供低延迟和高吞吐量。而TensorRT-LLM是在TensorRT基础上针对大模型进一步…
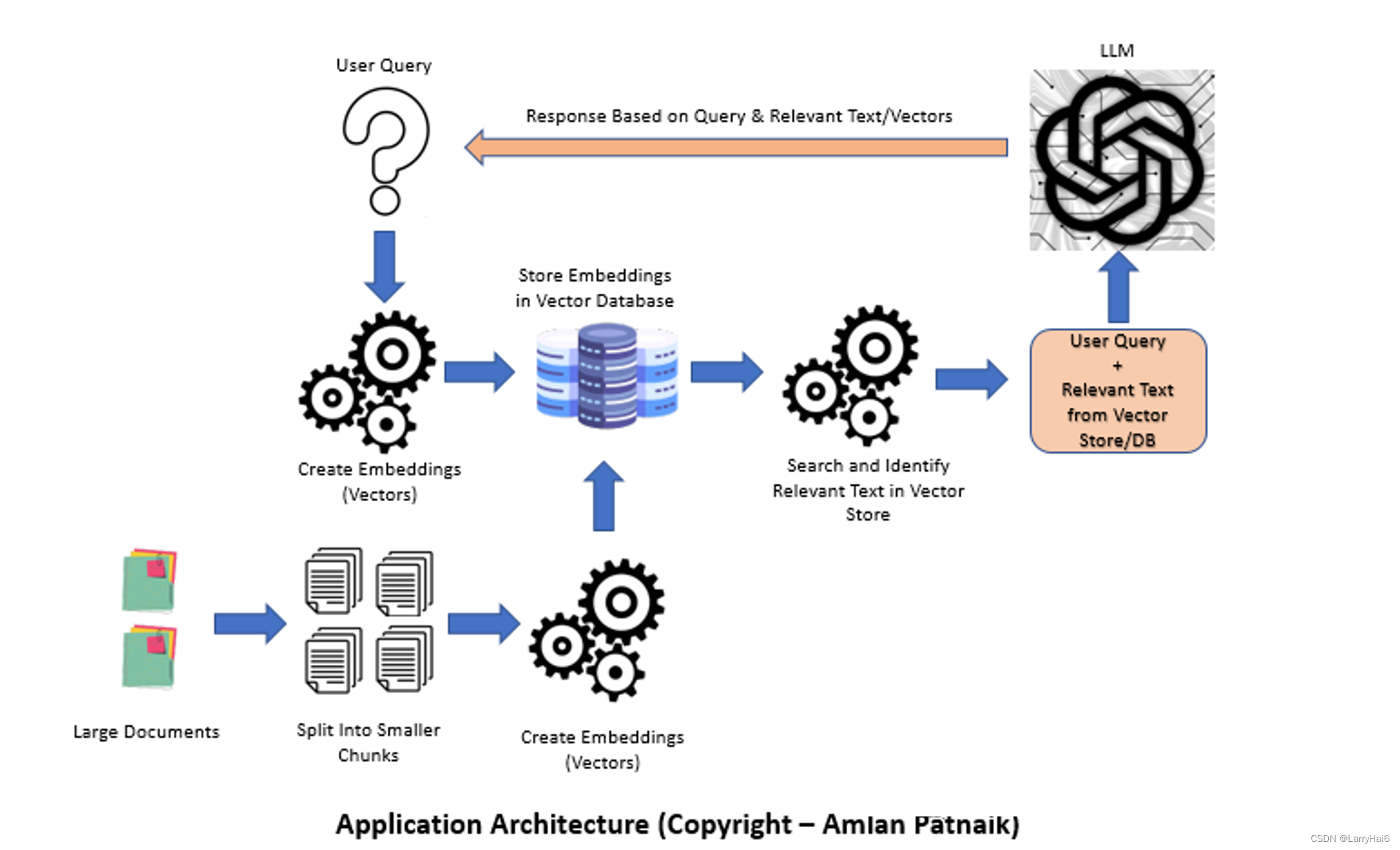
生成式AI - 基于大模型的应用架构与方案
这篇文章探讨了使用文档加载器、嵌入、向量存储和提示模板构建基于语言模型(LLM)应用程序的过程。由于其生成连贯且上下文相关的文本的能力,LLM在自然语言处理任务中变得越来越受欢迎。本文讨论了LLM的重要性,比较了微调和上下文注入方法,介绍…
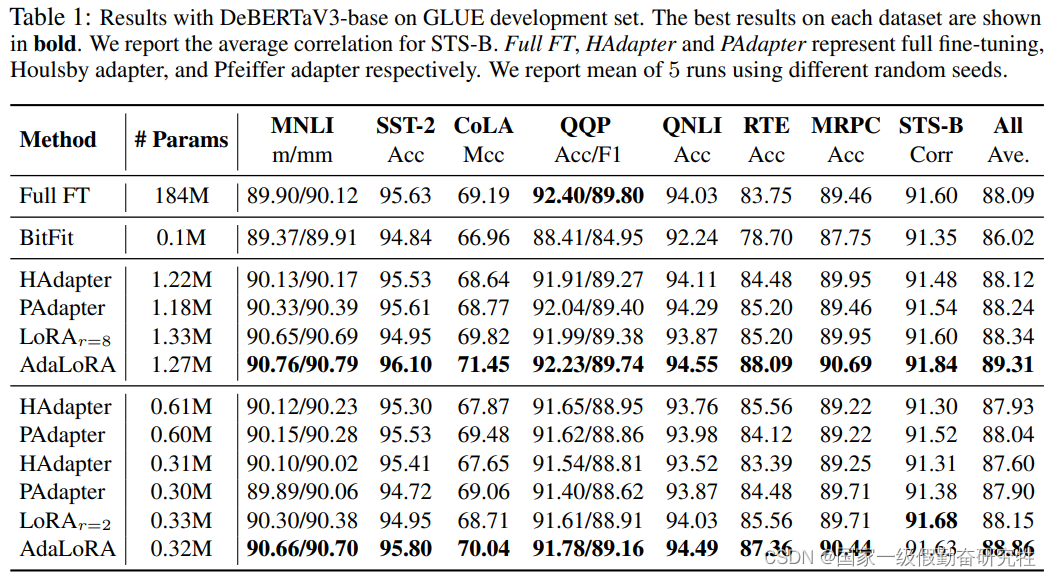
PEFT(高效微调)方法一览
PEFT论文解读2019-2023 2019-Adapter Tuning2019-PALs2020-Adapter-Fusion2021-Adapter-Drop2021-Diff-Pruning2021-Prefix-Tuning2021-Prompt-Tuning2021-WARP2021-LoRA2021-P-Tuning2021-P-Tuning-V22022-BitFit2022-MAM-Adpater2022-UniPELT2023-AdaLoRA总结 本文旨在梳理20…

调研图基础模型(Graph Foundation Models)
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 图基础模型(Graph Foundation Models,简称 GFMs) 是一种经过预训练的图大模型,旨在处理不同领域的图数据和任务。让我们详细探讨一下这个概念。
Github …
薅!语雀致歉送6个月会员;万字教程讲透AI视频生成;提示词14个黄金设计法则;吴恩达AI职业规划指南 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 讯飞发布星火认知大模型 V3.0,并推出多款大模型产品 10月24日,科大讯飞正式发布「星火认知大模型V3.0」&#…

AI提示工程实战:从零开始利用提示工程学习应用大语言模型【文末送书-19】
文章目录 背景什么是提示工程?从零开始:准备工作设计提示调用大语言模型 实际应用示例文字创作助手代码生成持续优化与迭代数据隐私与安全性可解释性与透明度总结 AI提示工程实战:从零开始利用提示工程学习应用大语言模型【文末送书-19】⛳粉…
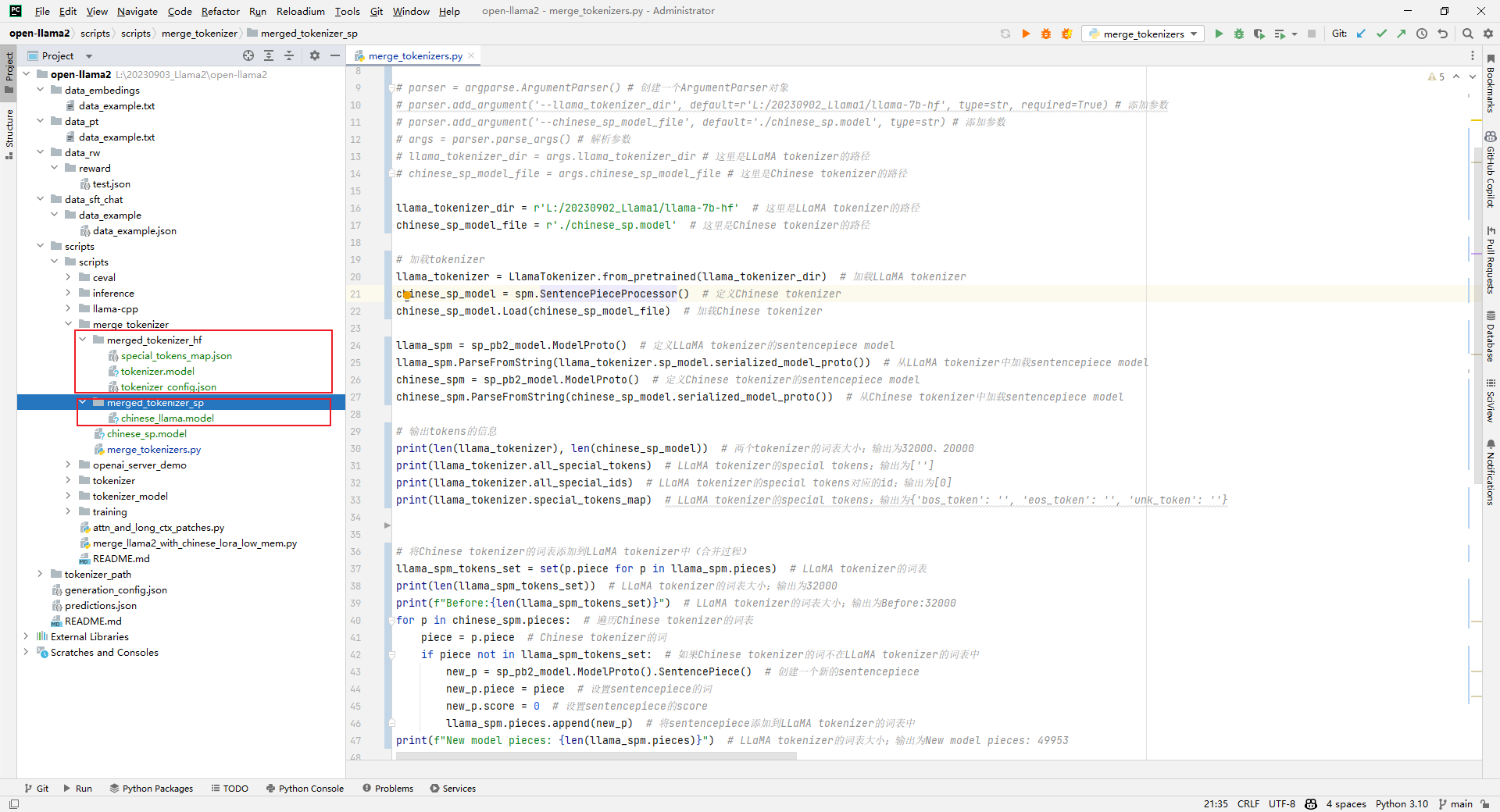
Llama2-Chinese项目:2.2-大语言模型词表扩充
因为原生LLaMA对中文的支持很弱,一个中文汉子往往被切分成多个token,因此需要对其进行中文词表扩展。思路通常是在中文语料库上训练一个中文tokenizer模型,然后将中文tokenizer与LLaMA原生tokenizer进行合并,最终得到一个扩展后的…
LLM:Vicuna 7B模型简单部署体验
0、引入1、保存权重文件到阿里云盘2、部署环境3、上传权重文件到30904、下载安装源码4.1 下载编译安装源码4.2 安装5、开始使用6、直接使用我的镜像立即开启人机对话Debug:可能的报错0、引入
随着ChatGPT的火热,科技公司们各显神通,针对大语…
论文分享 | NeurIPS 2023 使用大语言模型进行超参数优化
文章目录 一、前言二、主要内容1. 引言2. 方法3. 结果三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 Foundation Models for Decision Making Workshop at NeurIPS 2023:Using Large Language Models for Hyperparameter Optimization
Insight:我们…

想要更好地理解大模型架构?从计算参数量快速入手
编者按:要理解一种新的机器学习架构(以及其他任何新技术),最有效的方法就是从头开始实现它。然而,还有一种更简单的方法——计算参数数量。 通过计算参数数量,读者可以更好地理解模型架构,并检查…

AI之Sora:Sora(文本指令生成视频的里程碑模型)的简介(能力/安全性/技术细节)、使用方法、案例应用之详细攻略
AI之Sora:Sora(文本指令生成视频的里程碑模型)的简介(能力/安全性/技术细节)、使用方法、案例应用之详细攻略 导读:Sora 是OpenAI研发的一个可以根据文字描述生成视频的AI模型。它的主要特性、功能以及OpenAI在安全和应用方面的策略的核心要点如下所示&a…

DevChat:VSCode中基于大模型的AI智能编程助手
文章目录 1. 前言2. 安装2.1 注册新用户2.2 在VSCode中安装DevChat插件2.3 设置Access Key 3. 实战使用4. 总结 1. 前言 DevChat是由Merico公司精心打造的AI智能编程助手。它利用了最先进的大语言模型技术,像人类开发者一样高效地理解需求,并提供最佳的代…

解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
解锁ChatGLM-6B的潜力:优化大语言模型训练,突破任务困难与答案解析难题
LLM(Large Language Model)通常拥有大量的先验知识,使得其在许多自然语言处理任务上都有着不错的性能。
但,想要直接利用 LLM 完成…
利用提示工程,提升LLM将自然语言转化为SQL的准确性
大型语言模型 (LLM) 已展现出理解自然语言提示并生成连贯响应的卓越能力。 这为将自然语言翻译成 SQL 等结构化查询语言开辟了新的可能性。 过去,编写 SQL 查询需要技术专业知识,而LLM允许任何人用简单的英语描述他们想要的内容,并自动生成相…
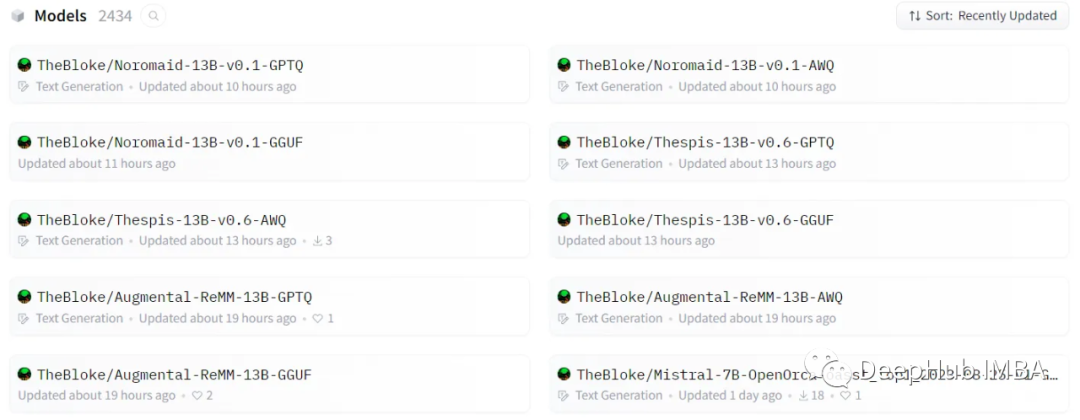
大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。
说明:每次加载LLM示例后,建议清除缓存,以…
【LLM 】7个基本的NLP模型,为ML应用程序赋能
在上一篇文章中,我们已经解释了什么是NLP及其在现实世界中的应用。在这篇文章中,我们将继续介绍NLP应用程序中使用的一些主要深度学习模型。
BERT
来自变压器的双向编码器表示(BERT)由Jacob Devlin在2018年的论文《BERT:用于语言…
网页动画科普LLM原理;淘宝推出AI试衣间;爆火的AI极简人像;100天创业日程表;Llama 2详解 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 Meta Connect 2023,发布基于 LLama 2 的AI聊天助手和虚拟角色 9月27日-28日,Meta 举办了年度重要会议 Meta Co…
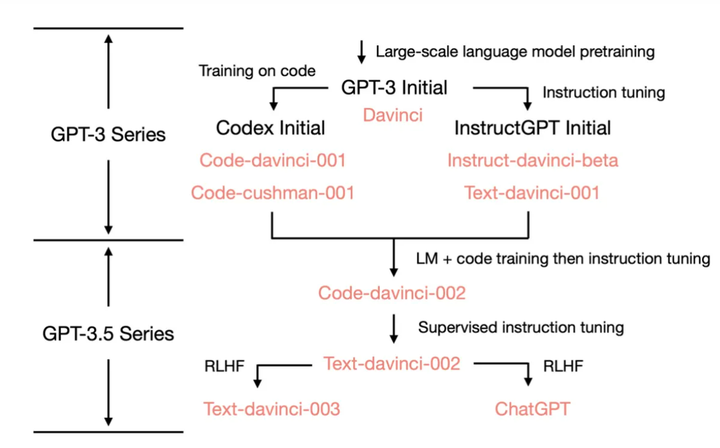
大语言模型的开山之作—探秘GPT系列:GPT-1-GPT2-GPT-3的进化之路
模型模型参数创新点评价GPT1预训练微调, 创新点在于Task-specific input transformations。GPT215亿参数预训练PromptPredict, 创新点在于Zero-shotZero-shot新颖度拉满,但模型性能拉胯GPT31750亿参数预训练PromptPredict, 创新点…

GPT内功心法:搜索思维到GPT思维的转换
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
SORA和大语言模型的区别
OpenAI的文生视频模型SORA与大语言模型(LLM)的主要区别在于它们的应用领域和处理的数据类型,数据处理能力、技术架构、多模态能力和创新点。SORA作为一款专注于视频生成的模型,展现了在处理视觉数据方面的独特优势和创新能力。
1…
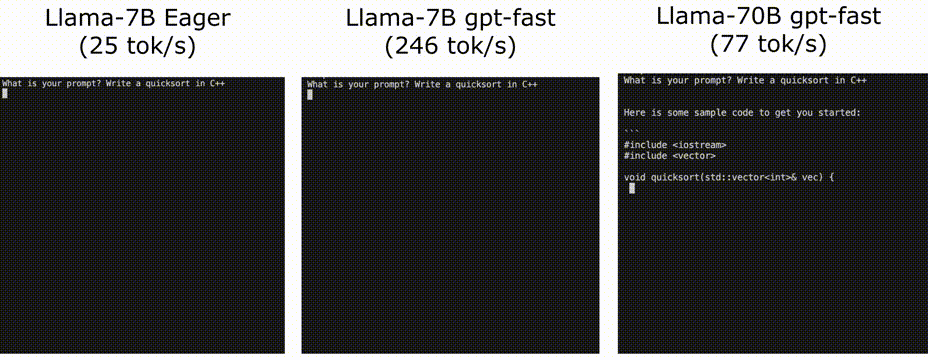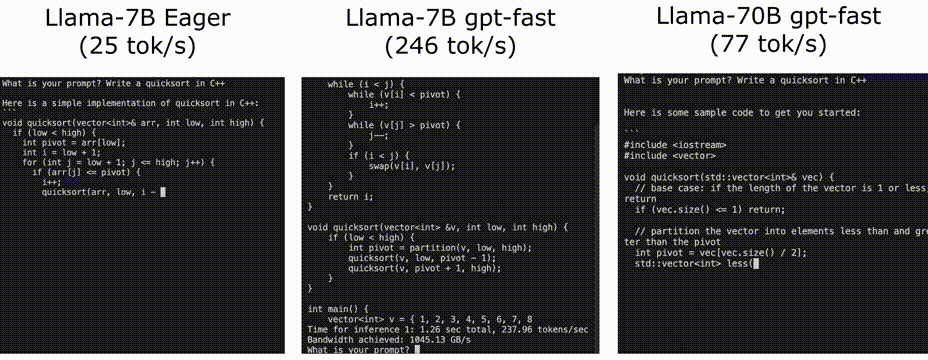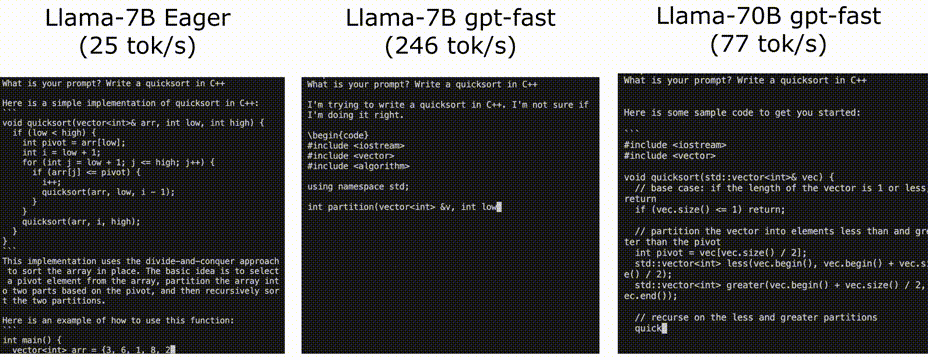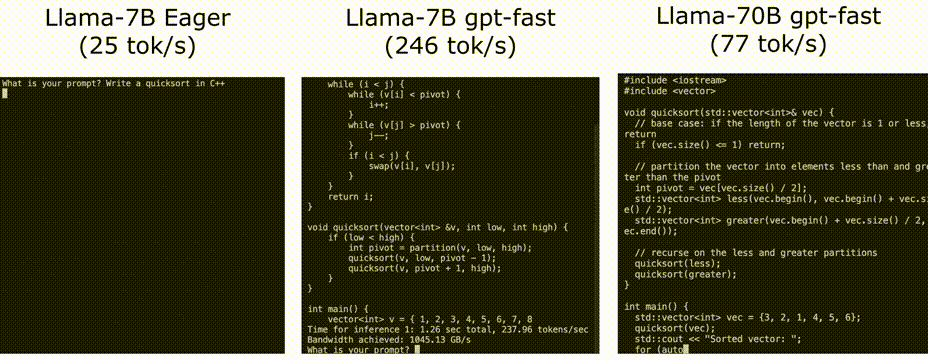
使用PyTorch II的新特性加快LLM推理速度
Pytorch团队提出了一种纯粹通过PyTorch新特性在的自下而上的优化LLM方法,包括:
Torch.compile: PyTorch模型的编译器
GPU量化:通过降低精度操作来加速模型
推测解码:使用一个小的“草稿”模型来加速llm来预测一个大的“目标”模型的输出
张量并行:通过在多个设备…

【AI视野·今日NLP 自然语言处理论文速览 第六十二期】Wed, 25 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 25 Oct 2023 (showing first 100 of 112 entries) Totally 100 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
MuSR: Testing the Limits of Chain-of-thought with Multistep Soft R…
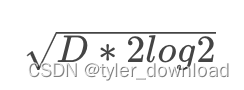
python 实现 AIGC 大模型中的概率论:生日问题的公式推导
在前两节中,我们推导了生日问题的求解算法,但在数学上的最终目标就是希望能针对问题推导出一个简洁漂亮的公式,就像爱因斯坦著名的质能方程 E MC^2 那样,毕竟数学是以符号逻辑来看待世界本质的语言,所以絮絮叨叨不是数…
LLMs:大语言模型的核心技术之上下文窗口长度技术的简介(核心技术拆解)、发展历史、案例应用之详细攻略
LLMs:大语言模型的核心技术之上下文窗口长度技术的简介(核心技术拆解)、发展历史、案例应用之详细攻略 目录
上下文窗口长度技术的简介
1、上下文窗口长度技术的发展历史
(0)、综合对比

【AI视野·今日NLP 自然语言处理论文速览 第六十四期】Fri, 27 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 27 Oct 2023 Totally 80 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
torchdistill Meets Hugging Face Libraries for Reproducible, Coding-Free Deep Learning Studies: A Case …
机器学习笔记 大语言模型是如何运作的?一、语料库和N-gram模型
一、语料库 语言模型、ChatGPT和人工智能似乎无处不在。了解大型语言模型(LLM)“背后”发生的事情将是驾驭数字世界的关键。 首先在提示中键入一个单词,然后点击提交。您可以尝试新的提示,并根据需要多次重新生成响应。 这个我们称之为“T&C”的语言模型是在一…
CopilotHub招聘产品设计师;大模型岗位面试官的一线分享;AI应用创业的共识与非共识;LangChain学习手册 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 CopilotHub 招聘产品设计师,AI Agent C 端产品、远程工作、无限制带薪假期 https://app.copilothub.ai 这是一家成立于202…
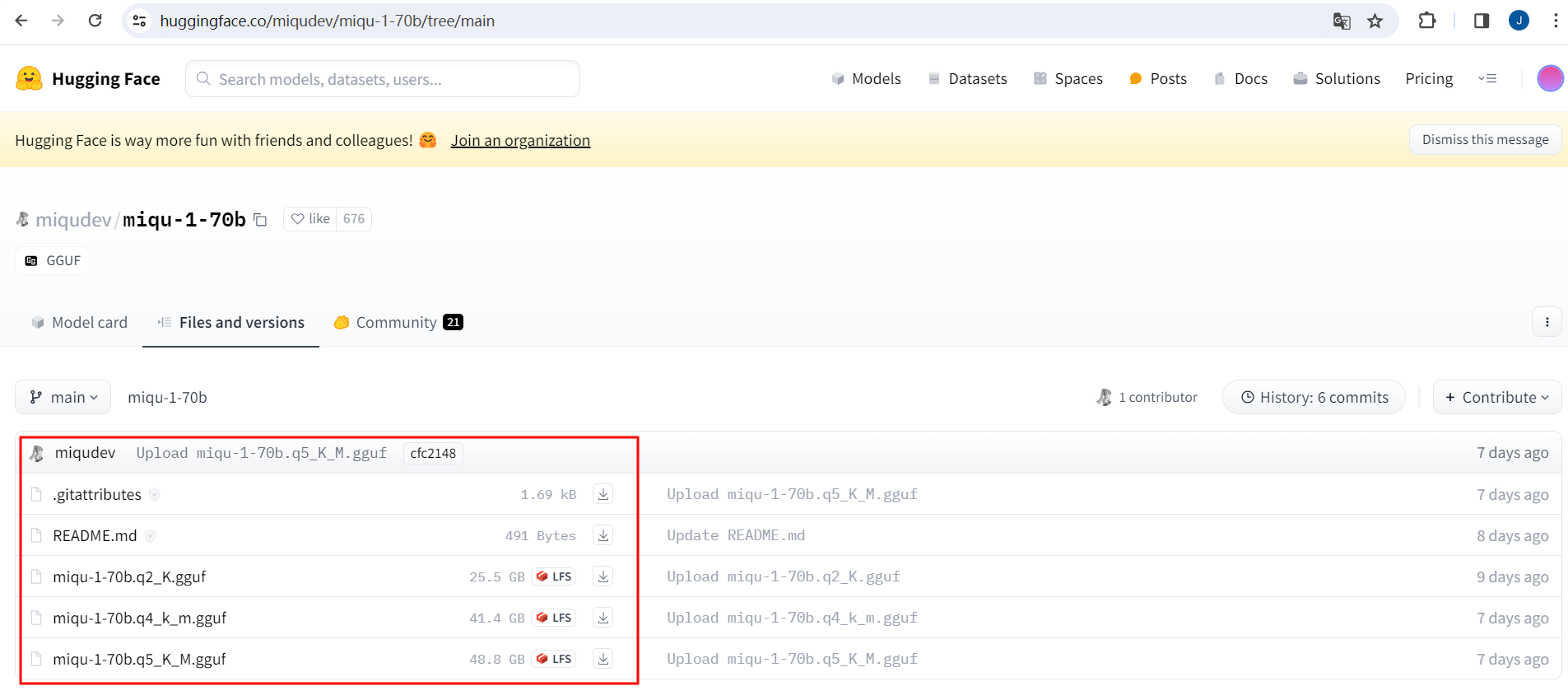
LLMs之miqu-1-70b:miqu-1-70b的简介、安装和使用方法、案例应用之详细攻略
LLMs之miqu-1-70b:miqu-1-70b的简介、安装和使用方法、案例应用之详细攻略 目录
miqu-1-70b的简介
miqu-1-70b的安装和使用方法
1、安装
2、使用方法
miqu-1-70b的案例应用 miqu-1-70b的简介
2024年1月28日,发布了miqu 70b,潜在系列中的…

【自然语言处理】【大模型】DeepMind的大模型Gopher
DeepMind的大模型Gopher《Scaling Language Models: Methods, Analysis & Insights from Training Gopher》论文:https://arxiv.org/pdf/2112.11446.pdf 相关博客 【自然语言处理】【大模型】DeepMind的大模型Gopher 【自然语言处理】【大模型】Chinchilla&…
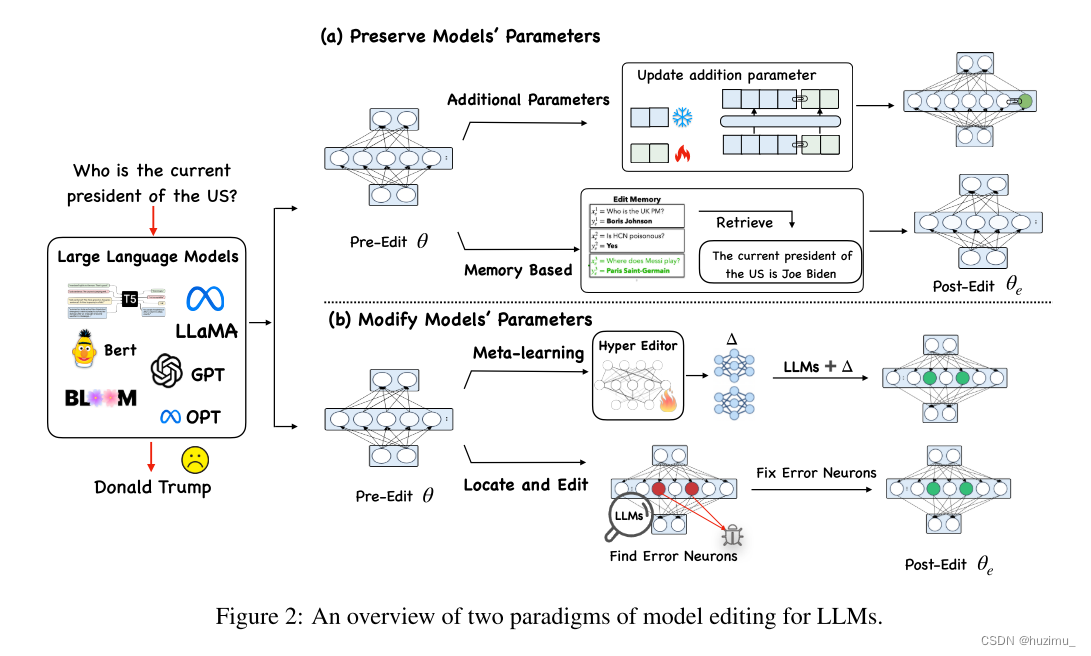
论文阅读:Editing Large Language Models: Problems, Methods, and Opportunities
Editing Large Language Models: Problems, Methods, and Opportunities
论文链接 代码链接
摘要
由于大语言模型(LLM)中可能存在一些过时的、不适当的和错误的信息,所以有必要纠正模型中的相关信息。如何高效地修改模型中的相关信息而不影…

港大提出图结构大语言模型:GraphGPT
1. 引言
图神经网络(Graph Neural Networks)已经成为分析和学习图结构数据的强大框架,推动了社交网络分析、推荐系统和生物网络分析等多个领域的进步。图神经网络的主要优势在于它们能够捕获图数据中固有的结构信息和依赖关系。利用消息传递…
9月大型语言模型研究论文总结
大型语言模型(llm)在今年发展迅速,随着新一代模型不断地被开发,研究人员和工程师了解最新进展变得非常重要。本文总结9-10月期间发布了一些重要的LLM论文。
这些论文涵盖了一系列语言模型的主题,从模型优化和缩放到推理、基准测试和增强性能…
AnythingLLM:基于RAG方案构专属私有知识库(开源|高效|可定制)
一、前言
继OpenAI和Google的产品发布会之后,大模型的能力进化速度之快令人惊叹,然而,对于很多个人和企业而言,为了数据安全不得不考虑私有化部署方案,从GPT-4发布以来,国内外的大模型就拉开了很明显的差距…

究诸经典,探寻大模型演变之踪迹
编者按:在仅仅五年的时间里,大语言模型、transformers几乎完全改变了自然语言处理领域。 为了便于快速、扎实、深入地学习大语言模型,本文整理一个简单的经典学术资料列表,供正在入门中的机器学习研究人员和开发者参考。 以下是译…
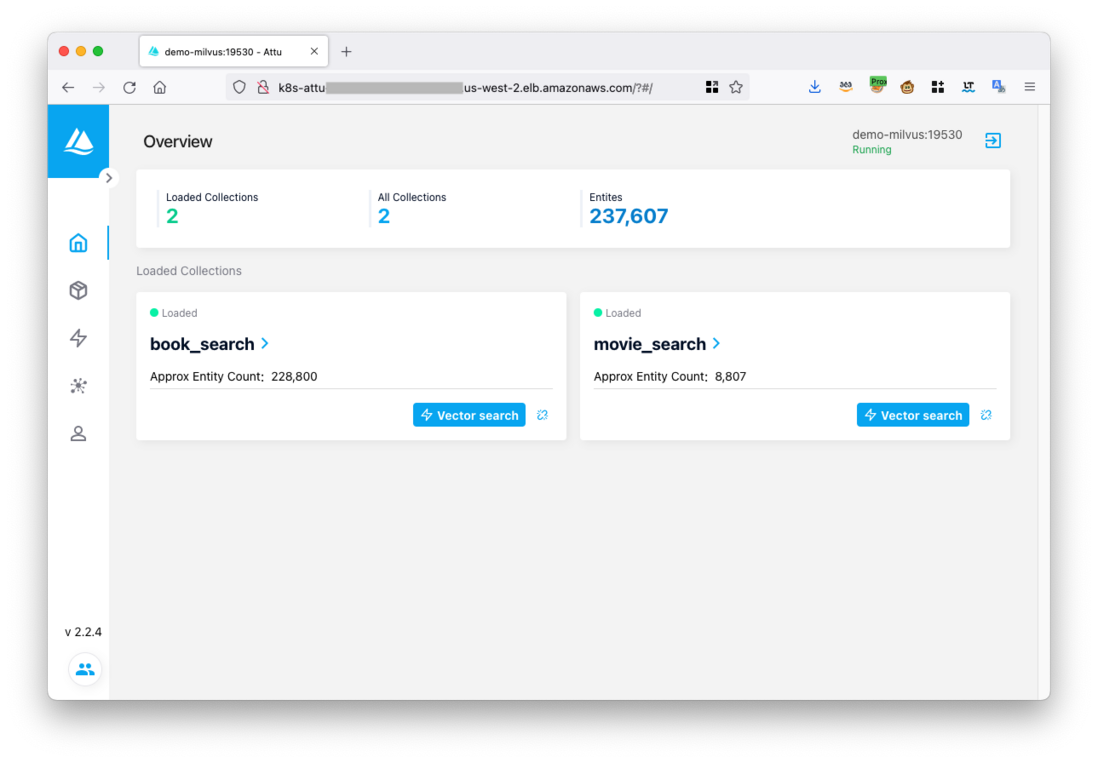
基于 Amazon EKS 搭建开源向量数据库 Milvus
一、前言
生成式 AI(Generative AI)的火爆引发了广泛的关注,也彻底点燃了向量数据库(Vector Database)市场,众多的向量数据库产品开始真正出圈,走进大众的视野。
根据 IDC 的预测,…
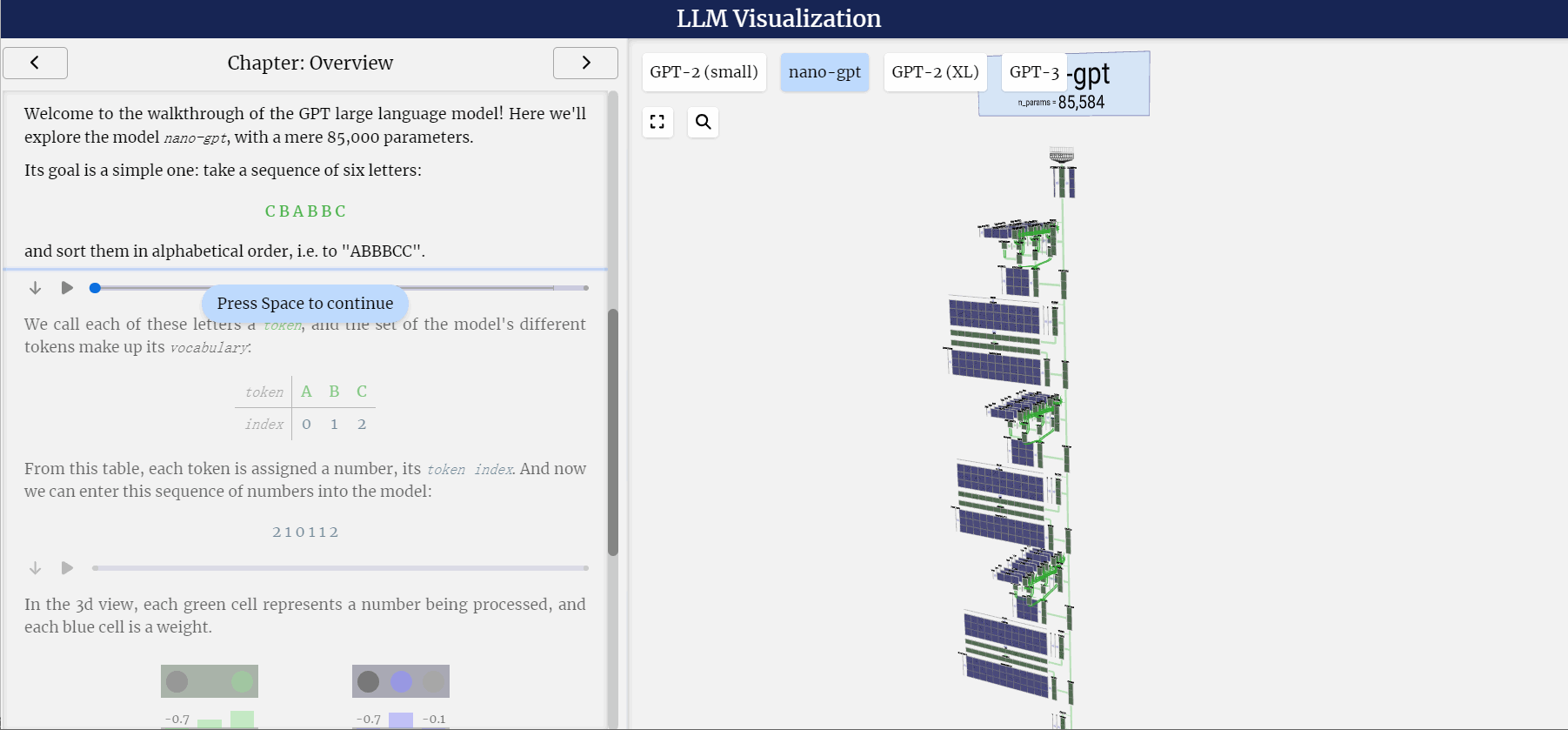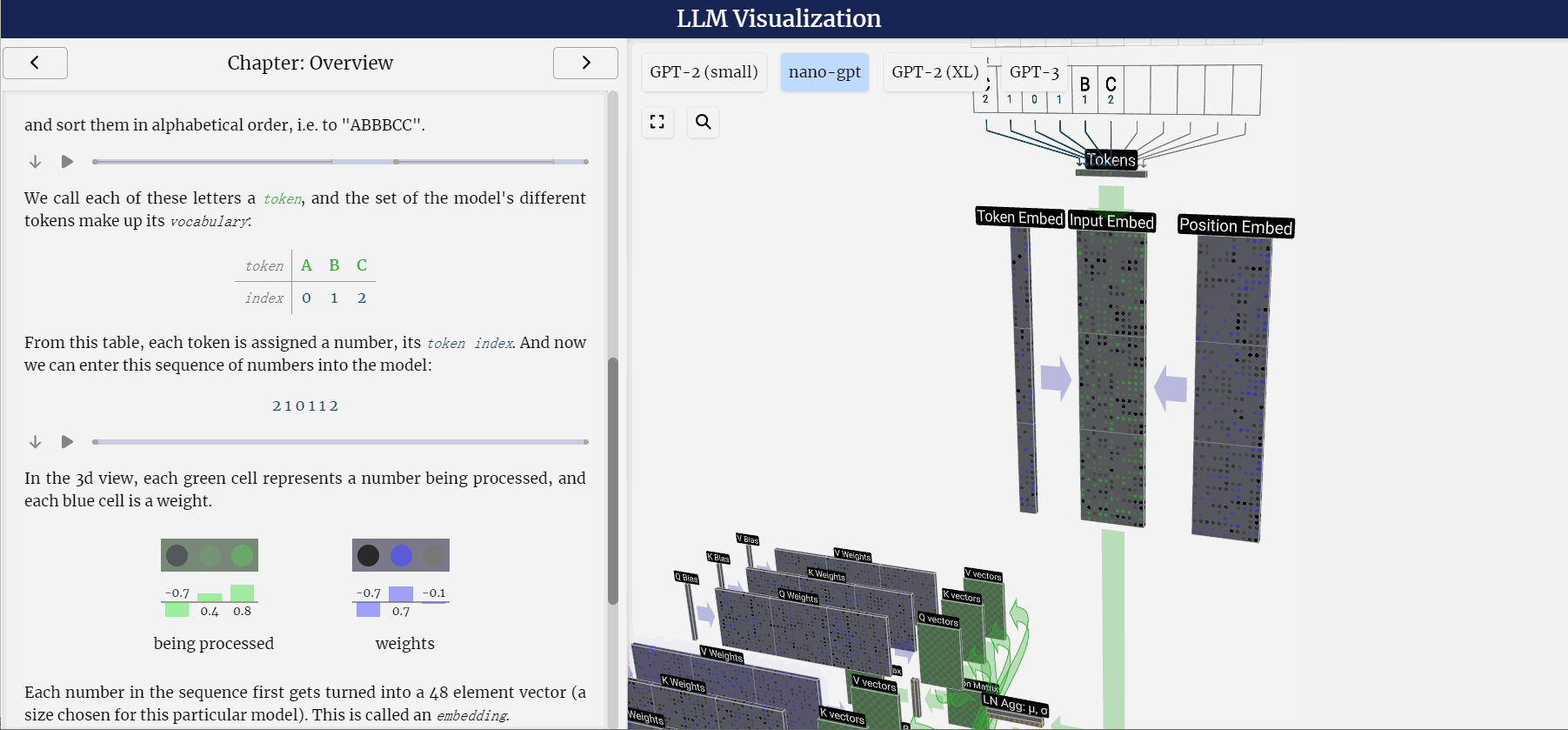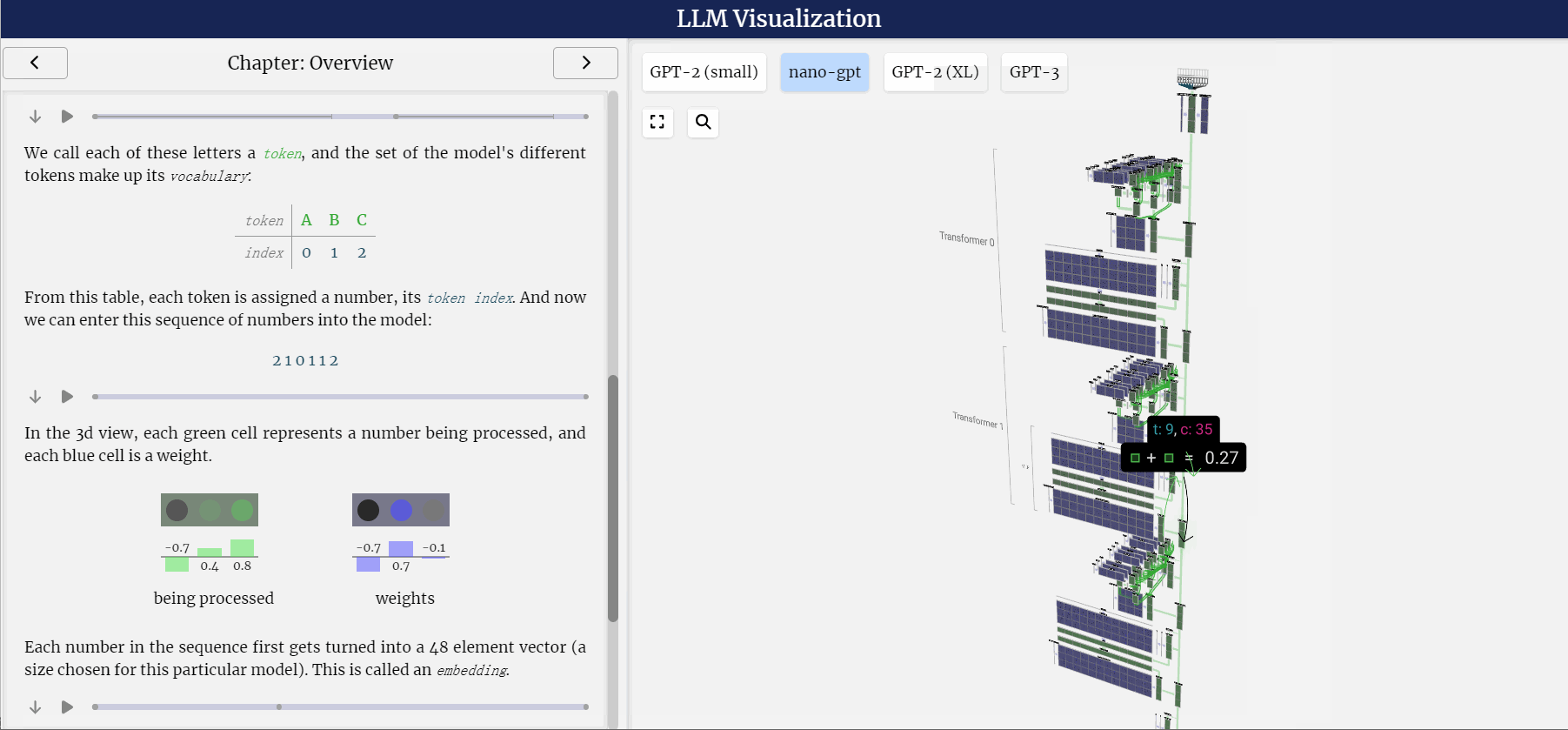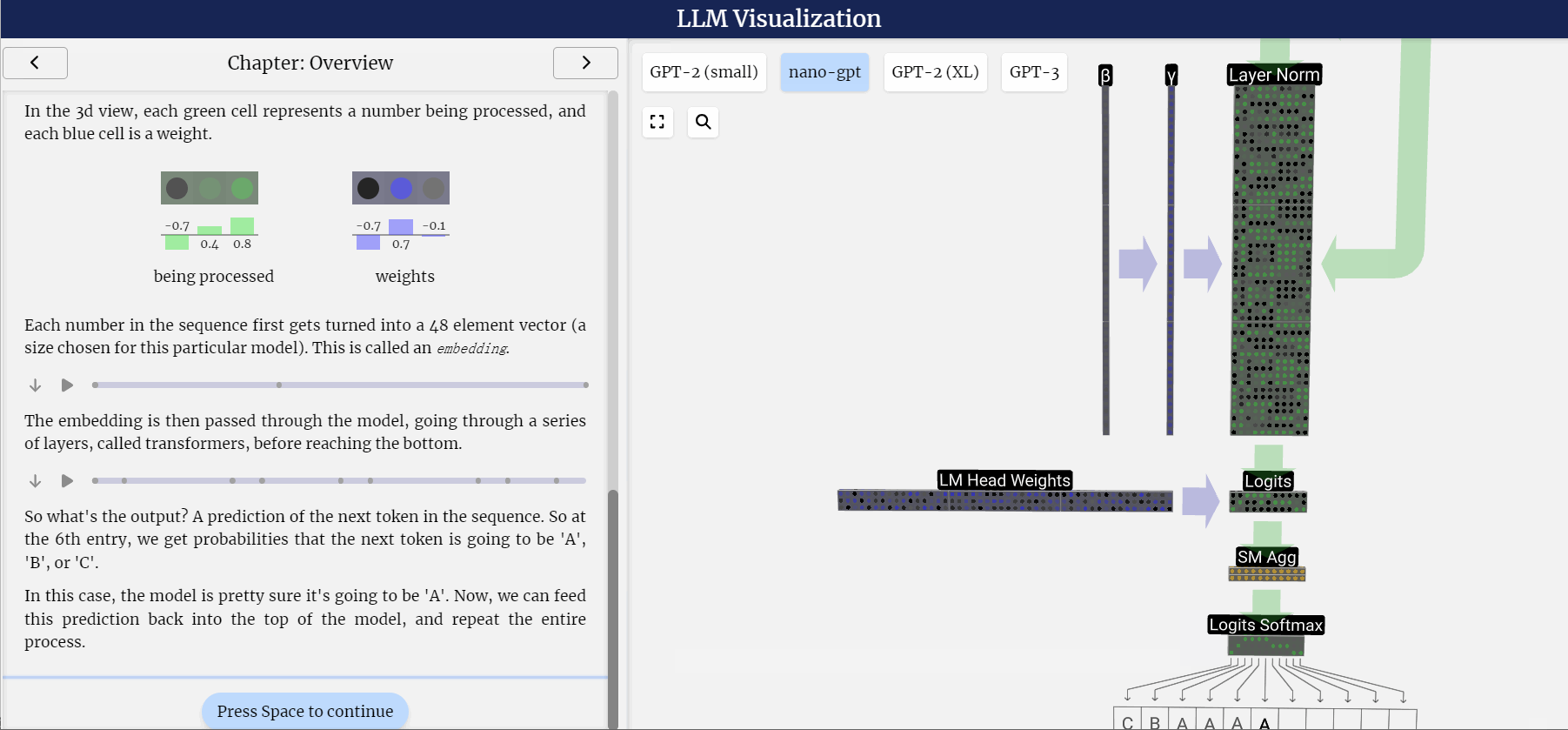
LLM之llm-viz:llm-viz(3D可视化GPT风格LLM)的简介、安装和使用方法、案例应用之详细攻略
LLM之llm-viz:llm-viz(3D可视化GPT风格LLM)的简介、安装和使用方法、案例应用之详细攻略 目录
llm-viz的简介
1、LLM可视化
2、CPU模拟(WIP;尚未公开!)
llm-viz的安装和使用方法
llm-viz的案例应用
1、三维可视化…
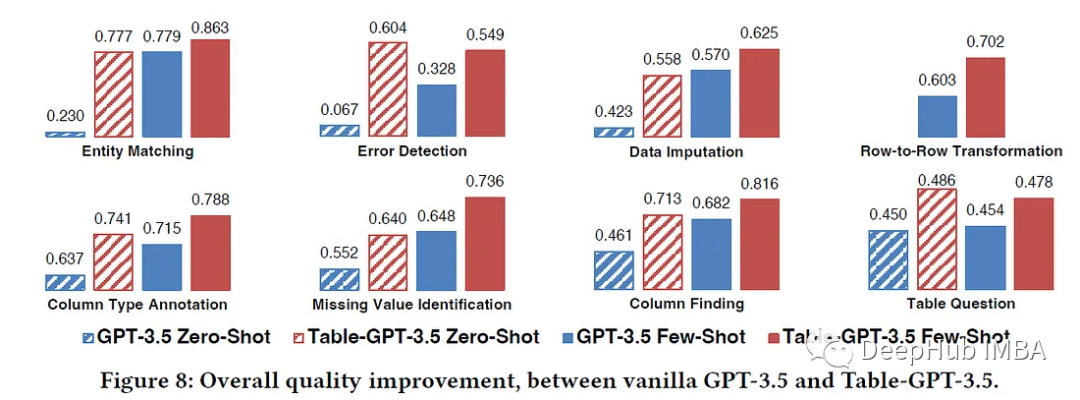
Table-GPT:让大语言模型理解表格数据
llm对文本指令非常有用,但是如果我们尝试向模型提供某种文本格式的表格数据和该表格上的问题,LLM更有可能产生不准确的响应。
在这篇文章中,我们将介绍微软发表的一篇研究论文,“Table-GPT: Table- tuning GPT for Diverse Table…

AI:人工智能领域AI工具产品集合分门别类(文本类、图片类、视频类、音频类、多模态类)的简介、使用方法(持续更新)之详细攻略
AI:人工智能领域AI工具产品集合分门别类(文本类、图片类、视频类、音频类、多模态类)的简介、使用方法(持续更新)之详细攻略 导读:由于ChatGPT、GPT-4近期火爆整个互联网,掀起了人工智能相关的二次开发应用的热潮,博主同时也应广大…

大模型训练数据多样性的重要性
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
Python从零到一构建GPT模型
只用Python和 torch框架,从零到一构建GPT模型,对大语言模型入门,了解GPT的内部网络结构,是一个很好示例。
Build_GPT_from_Scratch.ipynb

【AI视野·今日NLP 自然语言处理论文速览 第八十期】Fri, 1 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 1 Mar 2024 Totally 67 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Loose LIPS Sink Ships: Asking Questions in Battleship with Language-Informed Program Sampling Authors G…
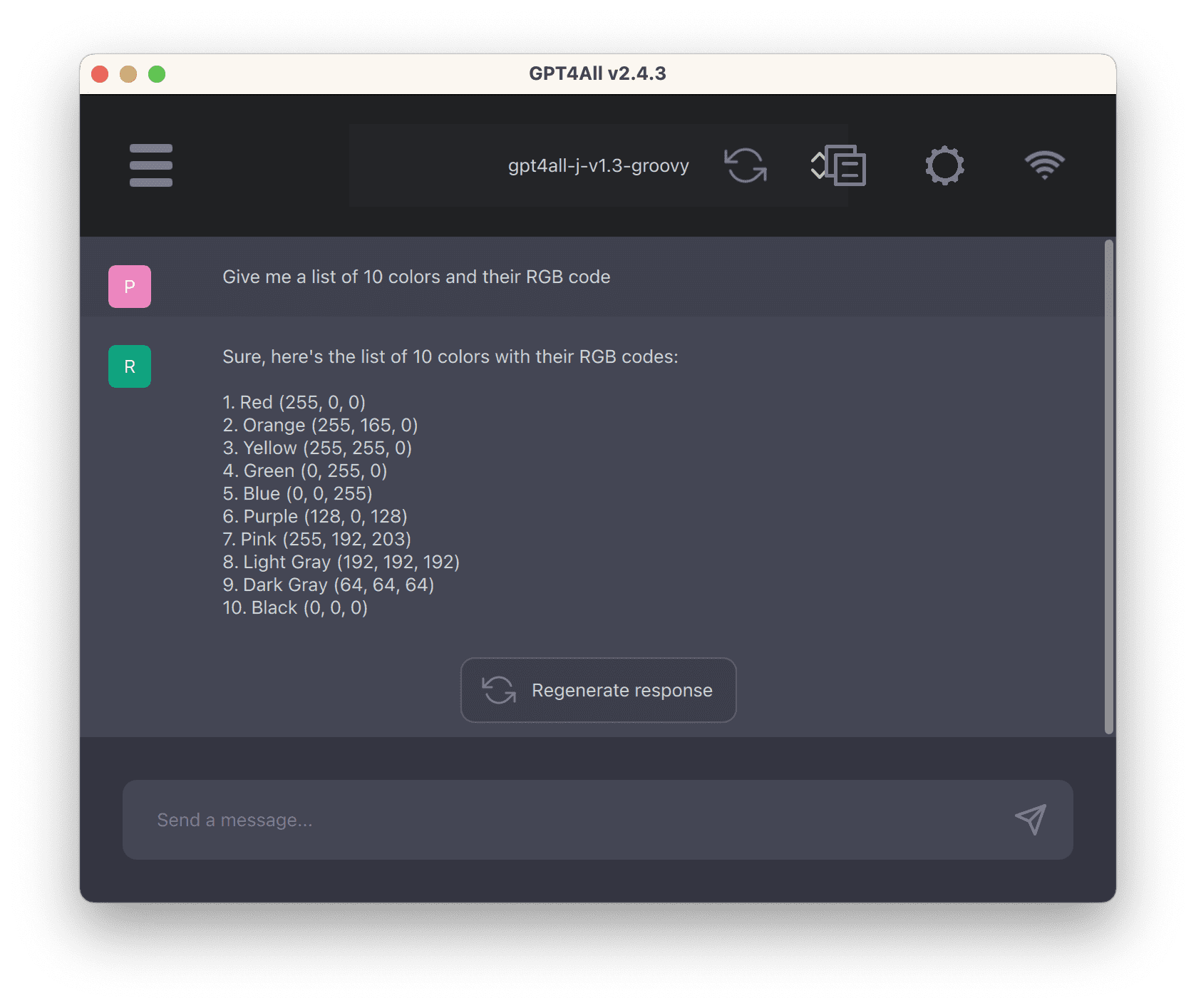
从 GPT4All 体验 LLM
推荐:使用 NSDT场景编辑器 助你快速搭建可编辑的3D应用场景 什么是 GPT4All?
术语“GPT”源自 Radford 等人 2018 年论文的标题“通过生成预训练提高语言理解”。本文描述了如何证明变压器模型能够理解人类语言。
从那时起,许多人尝试使用转…

大规模语言模型人类反馈对齐--强化学习
OpenAI 推出的 ChatGPT 对话模型掀起了新的 AI 热潮, 它面对多种多样的问题对答如流, 似乎已经打破了 机器和人的边界。这一工作的背后是大型语言模型 (Large Language Model,LLM) 生成领域的新训练范式:RLHF (Reinforcement Le…
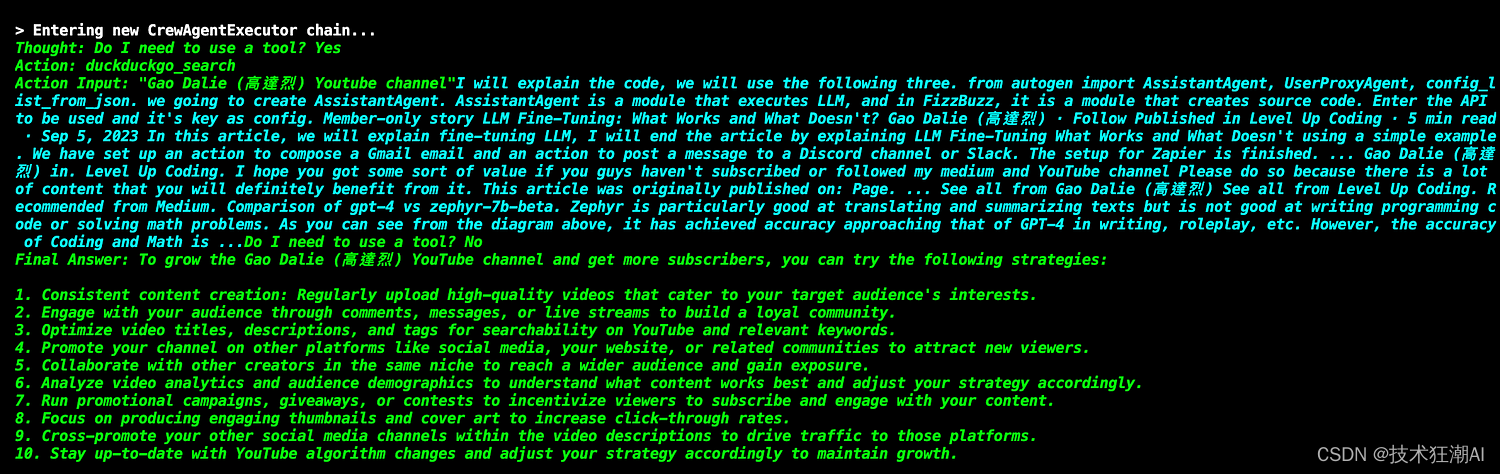
如何使用 CrewAI 构建协作型 AI Agents
一、前言
AI Agents 的开发是当前软件创新领域的热点。随着大语言模型 (LLM) 的不断进步,预计 AI 智能体与现有软件系统的融合将出现爆发式增长。借助 AI 智能体,我们可以通过一些简单的语音或手势命令,就能完成以往需要手动操作应用程序才能…

深入解析大语言模型显存占用:训练与推理
深入解析大语言模型显存占用:训练与推理 文章脉络 估算模型保存大小 估算模型在训练时占用显存的大小 全量参数训练 PEFT训练 估算模型在推理时占用显存的大小 总结 对于NLP领域的从业者和研究人员来说,有没有遇到过这样一个场景,你的…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.25-2024.03.31
文章目录~ 1.Gecko: Versatile Text Embeddings Distilled from Large Language Models2.Towards Greener LLMs: Bringing Energy-Efficiency to the Forefront of LLM Inference3.LUQ: Long-text Uncertainty Quantification for LLMs4.Draw-and-Understand: Leveraging Visua…

解读未知:文本识别算法的突破与实际应用
解读未知:文本识别算法的突破与实际应用
1.文本识别算法理论
背景介绍
文本识别是OCR(Optical Character Recognition)的一个子任务,其任务为识别一个固定区域的的文本内容。在OCR的两阶段方法里,它接在文本检测后面…
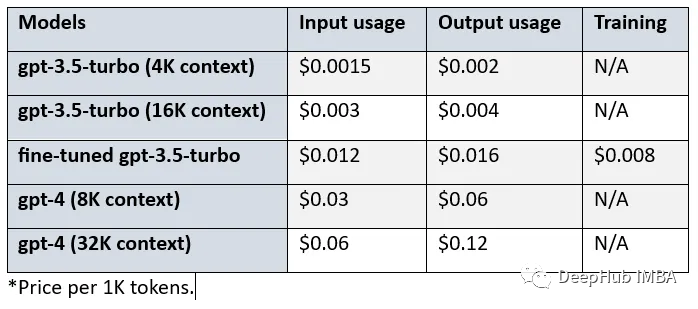
使用GPT-4生成训练数据微调GPT-3.5 RAG管道
OpenAI在2023年8月22日宣布,现在可以对GPT-3.5 Turbo进行微调了。也就是说,我们可以自定义自己的模型了。然后LlamaIndex就发布了0.8.7版本,集成了微调OpenAI gpt-3.5 turbo的功能
也就是说,我们现在可以使用GPT-4生成训练数据&a…
苹果最新的M3系列芯片对于大模型的使用来说未来价值如何?结果可能不太好!M3芯片与A100算力对比!
本文来自DataLearnerAI官方网站:苹果最新的M3系列芯片对于大模型的使用来说未来价值如何?结果可能不太好!M3芯片与A100算力对比! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051698716733526
M3系列芯…
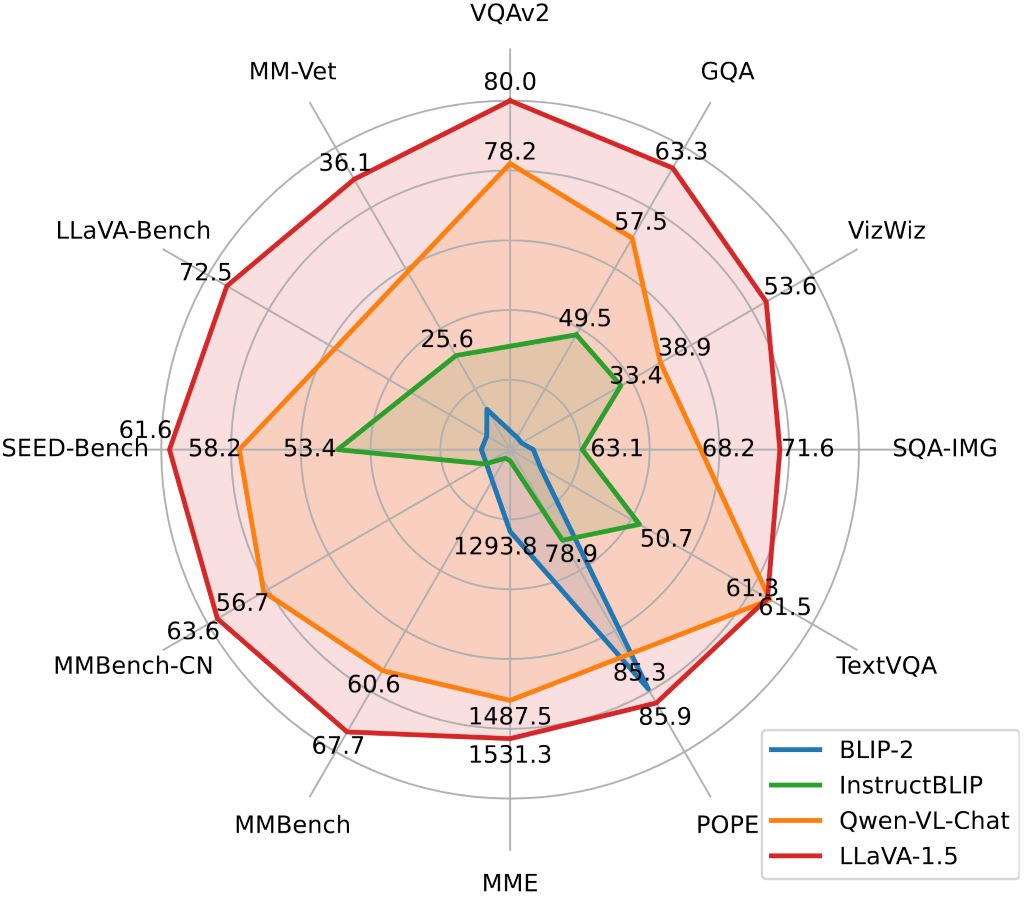
大规模语言LLaVA:多模态GPT-4智能助手,融合语言与视觉,满足用户复杂需求
大规模语言LLaVA:多模态GPT-4智能助手,融合语言与视觉,满足用户复杂需求
一个面向多模式GPT-4级别能力构建的助手。它结合了自然语言处理和计算机视觉,为用户提供了强大的多模式交互和理解。LLaVA旨在更深入地理解和处理语言和视…

【AI视野·今日NLP 自然语言处理论文速览 第六十三期】Thu, 26 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 26 Oct 2023 Totally 89 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
LLM-FP4: 4-Bit Floating-Point Quantized Transformers Authors Shih yang Liu, Zechun Liu, Xijie Huang, P…

AI工程师招募;60+开发者AI工具清单;如何用AI工具读懂插件源码;开发者出海解读;斯坦福LLM课程 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 一则AI工程师招募信息:新领域需要新技能 Vision Flow (目的涌现) 是一家基于 AGI 原生技术的创业公司,是全球探…

【AI视野·今日NLP 自然语言处理论文速览 第四十三期】Thu, 28 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 28 Sep 2023 Totally 38 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Cross-Modal Multi-Tasking for Speech-to-Text Translation via Hard Parameter Sharing Authors Brian Yan,…

CodeLlama本地部署的实战方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

十分钟部署清华 ChatGLM-6B,实测效果超预期(Linux版)
前段时间,清华公布了中英双语对话模型 ChatGLM-6B,具有60亿的参数,初具问答和对话功能。
最!最!最重要的是它能够支持私有化部署,大部分实验室的服务器基本上都能跑起来。因为条件特殊,实验室网…
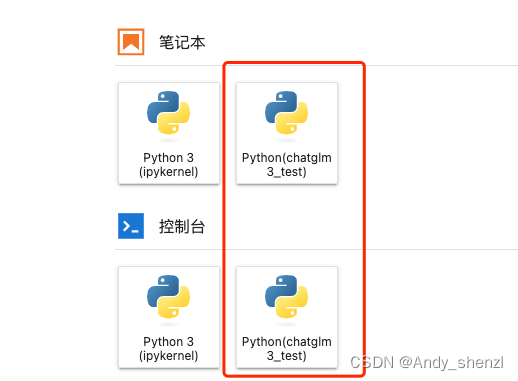
6、ChatGLM3-6B 部署实践
一、ChatGLM3-6B介绍与快速入门 ChatGLM3 是智谱AI和清华大学 KEG 实验室在2023年10月27日联合发布的新一代对话预训练模型。ChatGLM3-6B 是 ChatGLM3 系列中的开源模型,免费下载,免费的商业化使用。 该模型在保留了前两代模型对话流畅、部署门槛低等众多…

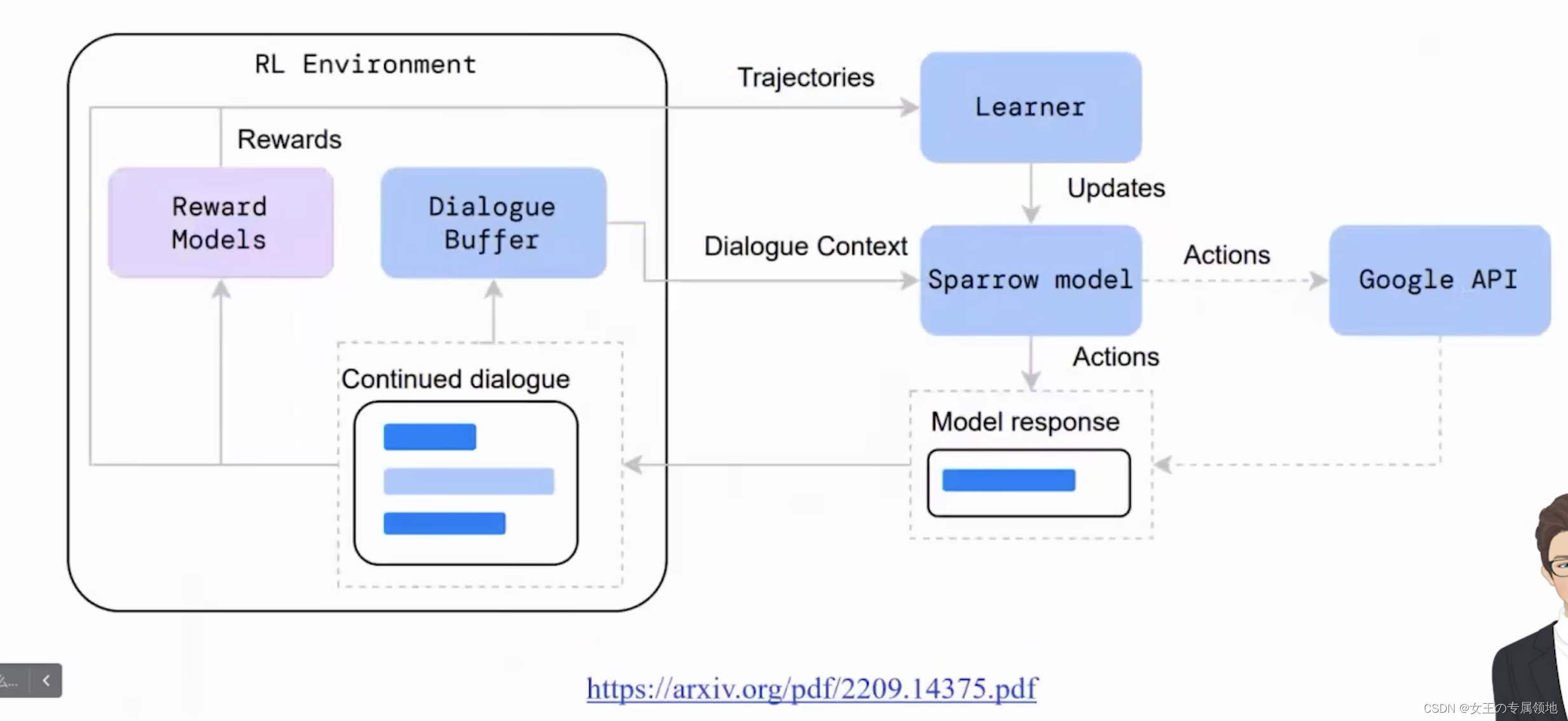
一文读懂「RLHF,Reinforcement Learning from Human Feedback」基于人类反馈的进行强化学习
一、背景由来
过去几年里,以ChatGPT为代表的基于prompt范式的大型语言模型 (Large Language Model,LLM) 取得了巨大的成功。然而,对生成结果的评估是主观和依赖上下文的,这些结果难以用现有的基于规则的文本生成指标 (如 BLUE 和…
ChatGPT等大语言模型为什么没有智能
今天我们来闲聊聊chatGPT,然后带出一些目前神经网络或者更大一些人工智能存在的问题,仅作抛砖引玉。我不管OpenAI用什么方式炒作,Q*也好,AI自我意识也好,董事会内斗也罢;首先它的成绩还是非常出色的&#x…

【自然语言处理】BitNet b1.58:1bit LLM时代
论文地址:https://arxiv.org/pdf/2402.17764.pdf 相关博客 【自然语言处理】BitNet b1.58:1bit LLM时代 【自然语言处理】【长文本处理】RMT:能处理长度超过一百万token的Transformer 【自然语言处理】【大模型】MPT模型结构源码解析(单机版)…
激发创新,助力研究:CogVLM,强大且开源的视觉语言模型亮相
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…

学习大语言模型(LLM),从这里开始
在见识了ChatGPT的各种强大能力后,不少 NLP一线从业人员很自然地想到,以后开发者只要借助 ChatGPT,就可以做到现在大部分NLP工程师在做的事,比如文本分类、实体抽取、文本推理等。甚至随着大语言模型(largelanguagemod…
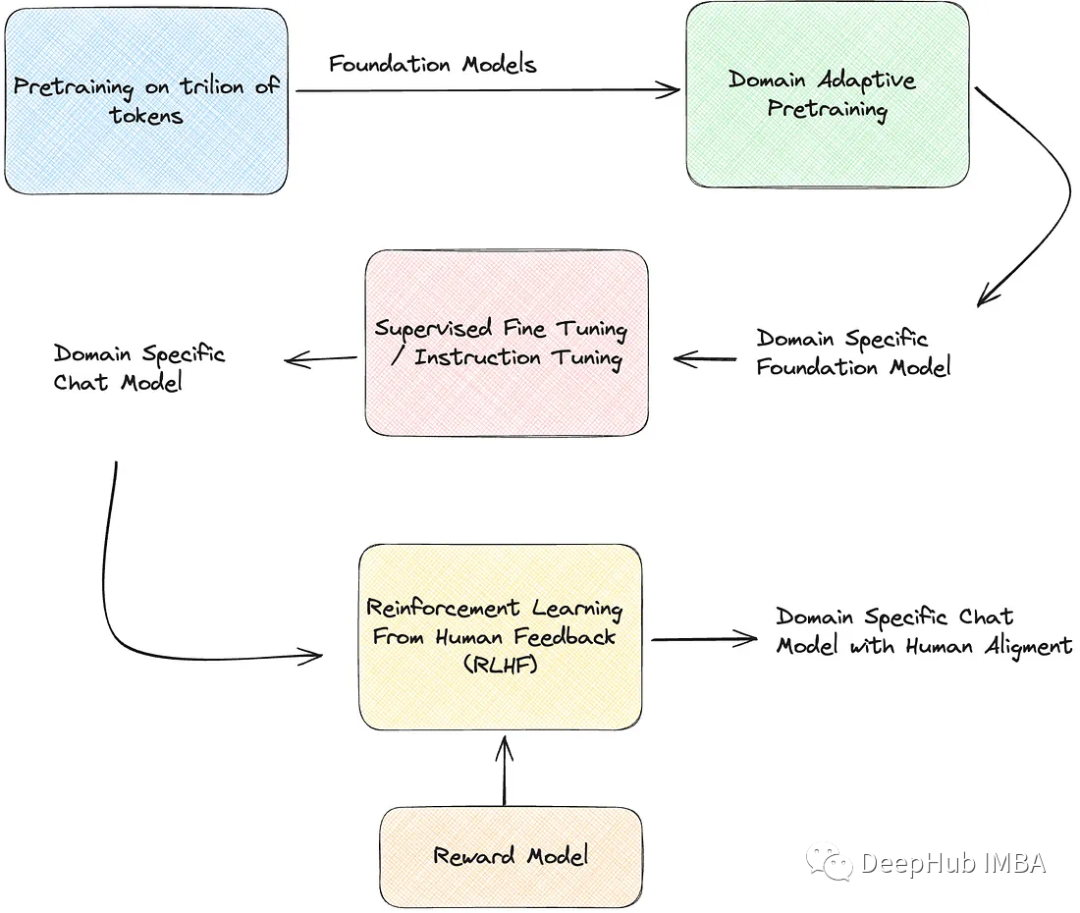
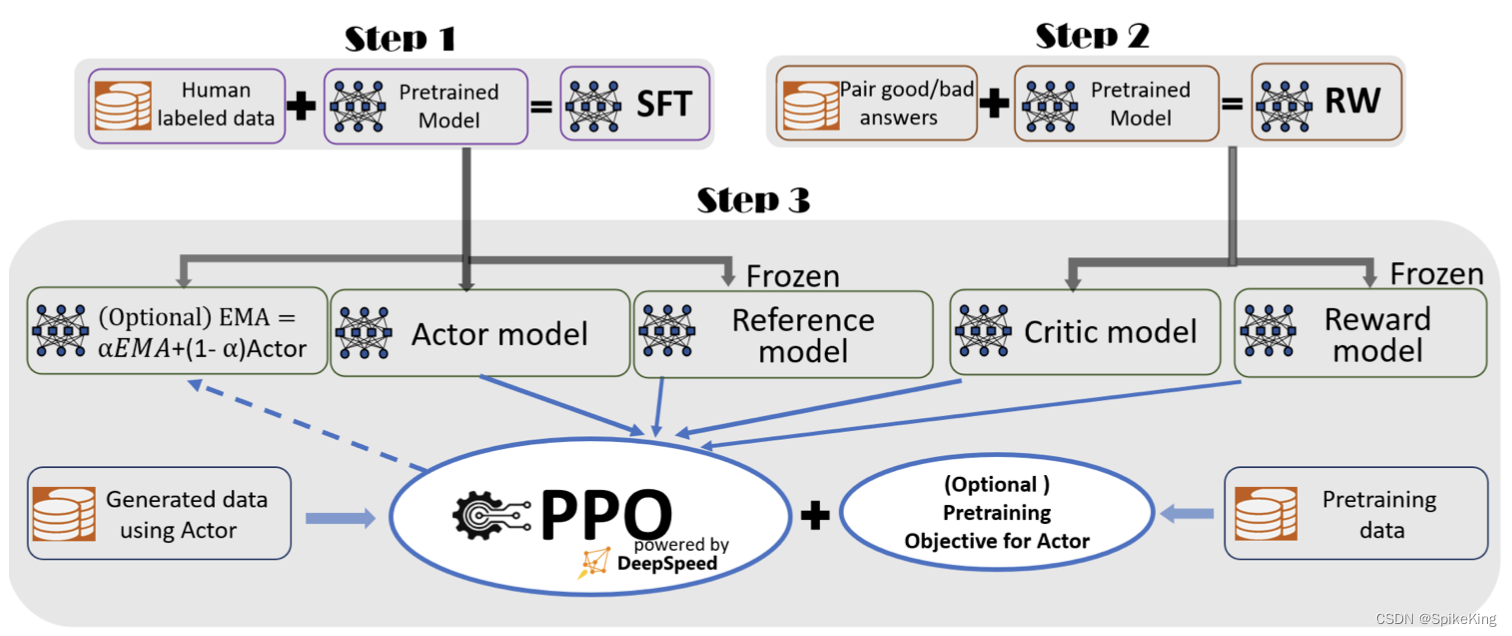
使用Huggingface创建大语言模型RLHF训练流程的完整教程
ChatGPT已经成为家喻户晓的名字,而大语言模型在ChatGPT刺激下也得到了快速发展,这使得我们可以基于这些技术来改进我们的业务。
但是大语言模型像所有机器/深度学习模型一样,从数据中学习。因此也会有garbage in garbage out的规则。也就是说…
GPTs - 定制版的ChatGPT
GPTs指的是定制版的ChatGPT (Custom versions of ChatGPT),它试图解决为不同用途定制ChatGPT的需求。为了实现这一点,
GPTs 提供了指令 (Instructions),知识 (Knowledge),能力 (Capabilities),动作 (Actions) 等功能&…
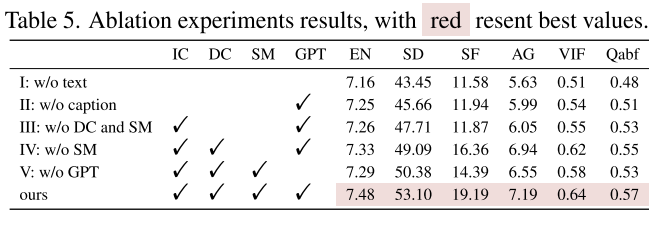
Image Fusion via Vision-Language Model【文献阅读】
阅读目录 文献阅读AbstractIntroduction3. Method3.1. Problem Overview3.2. Fusion via Vision-Language Model 4. Vision-Language Fusion Datasets5. Experiment5.1Infrared and Visible Image Fusion 6. Conclusion个人总结 文献阅读 原文下载:https://arxiv.or…
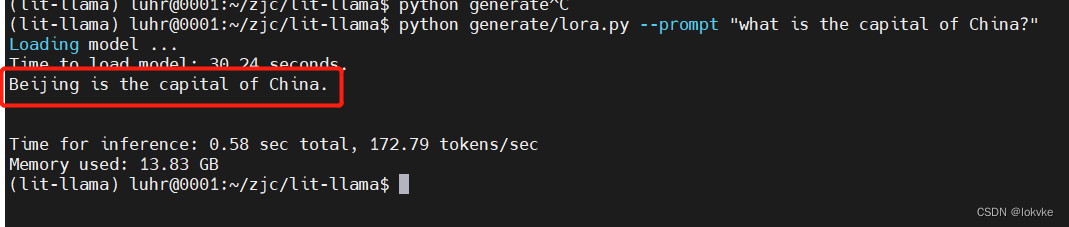
快速训练自己的大语言模型:基于LLAMA-7B的lora指令微调
目录 1. 选用工程:lit-llama2. 下载工程3. 安装环境4. 下载LLAMA-7B模型5. 做模型转换6. 初步测试7. 为什么要进行指令微调?8. 开始进行指令微调8.1. 数据准备8.2 开始模型训练8.3 模型测试 前言: 系统:ubuntu 18.04显卡ÿ…
自然语言处理:大语言模型入门介绍
自然语言处理:大语言模型入门介绍 语言模型的历史演进大语言模型基础知识预训练Pre-traning微调Fine-Tuning指令微调Instruction Tuning对齐微调Alignment Tuning 提示Prompt上下文学习In-context Learning思维链Chain-of-thought提示开发(调用ChatGPT的…

![[LLM+AIGC] 01.应用篇之中文ChatGPT初探及利用ChatGPT润色论文对比浅析(文心一言 | 讯飞星火)](https://img-blog.csdnimg.cn/884dddb999f9445187be8174b7f6b9e3.jpeg#pic_center)
[LLM+AIGC] 01.应用篇之中文ChatGPT初探及利用ChatGPT润色论文对比浅析(文心一言 | 讯飞星火)
近年来,人工智能技术火热发展,尤其是OpenAI在2022年11月30日发布ChatGPT聊天机器人程序,其使用了Transformer神经网络架构(GPT-3.5),能够基于在预训练阶段所见的模式、统计规律和知识来生成回答,…
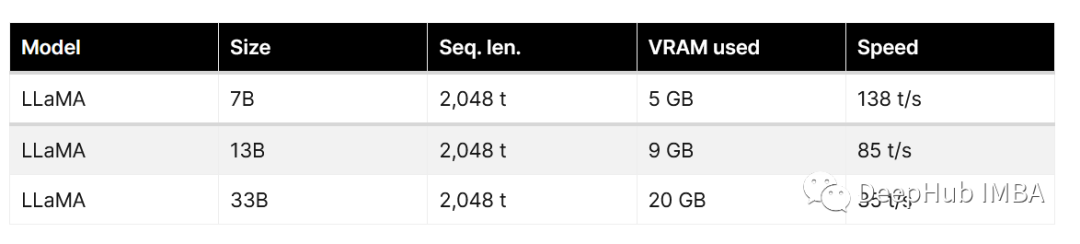
Llama-2 推理和微调的硬件要求总结:RTX 3080 就可以微调最小模型
大语言模型微调是指对已经预训练的大型语言模型(例如Llama-2,Falcon等)进行额外的训练,以使其适应特定任务或领域的需求。微调通常需要大量的计算资源,但是通过量化和Lora等方法,我们也可以在消费级的GPU上…

AIGC元年大模型发展现状手册
零、AIGC大模型概览
AIGC大模型在人工智能领域取得了重大突破,涵盖了LLM大模型、多模态大模型、图像生成大模型以及视频生成大模型等四种类型。这些模型不仅拓宽了人工智能的应用范围,也提升了其处理复杂任务的能力。a.) LLM大模型通过深度学习和自然语…
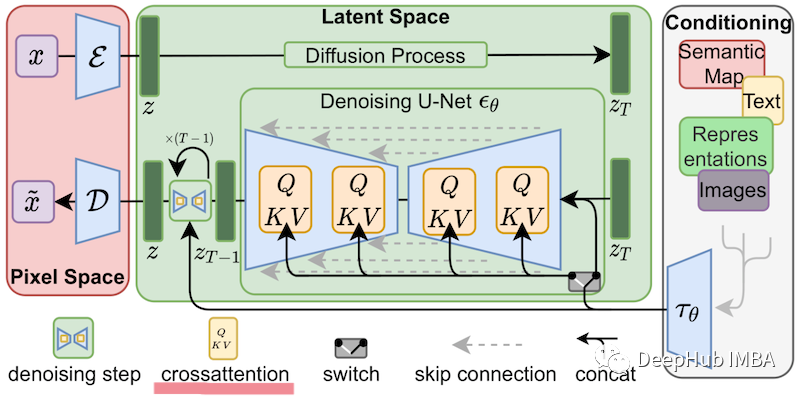
LoRA:大模型的低秩自适应微调模型
对于大型模型来说,重新训练所有模型参数的全微调变得不可行。比如GPT-3 175B,模型包含175B个参数吗,无论是微调训练和模型部署,都是不可能的事。所以Microsoft 提出了低秩自适应(Low-Rank Adaptation, LoRA),它冻结了预…
谷歌Gemini被骂了?让子弹飞一会儿;如何构建高效RAG系统;Pika是腐朽王朝的颠覆者;AGI将重塑组织架构;对话月之暗面杨植麟 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 👀 淘宝 X D.Design 堆友 | 淘宝年终好价节 AIGC 创作大赛 https://d.design/competition/taobao-promotion 淘宝携手堆友联合打造了「淘…

【LLM】FuseLLM:大模型融合trick-知识融合LLMs
前言
传统的模型融合方法分为集成的方法和权重合并的方法,这两种方法在以往的NLP的比赛中非常常见,是一种提分手段。然而,上述两种方法都需要预训练或者微调相应的模型。在大模型场景下,对每个源模型都进行初始化成本太高&#x…
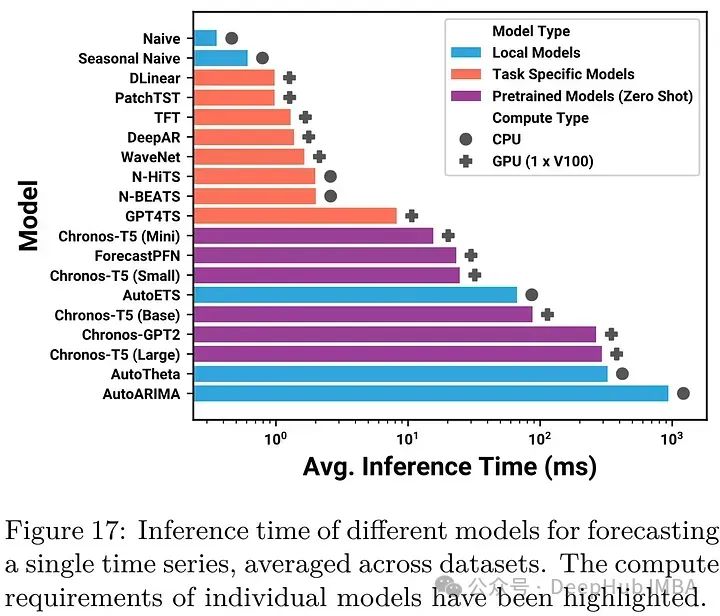
Chronos: 将时间序列作为一种语言进行学习
这是一篇非常有意思的论文,它将时间序列分块并作为语言模型中的一个token来进行学习,并且得到了很好的效果。 Chronos是一个对时间序列数据的概率模型进行预训练的框架,它将这些值标记为与基于transformer的模型(如T5)一起使用。模型将序列的…
大语言模型开发各个阶段的评估方法(未完)
大语言模型开发过程评估 1. 提出问题2. 大语言模型开发过程评估数据评估方法训练数据质量评估评价数据集或者基准的质量评估 模型评估方法评估基座模型评估通用大语言模型评估专用大语言模型 1. 提出问题
场景:我们要设计一个专有领域的大语言模型,设计…
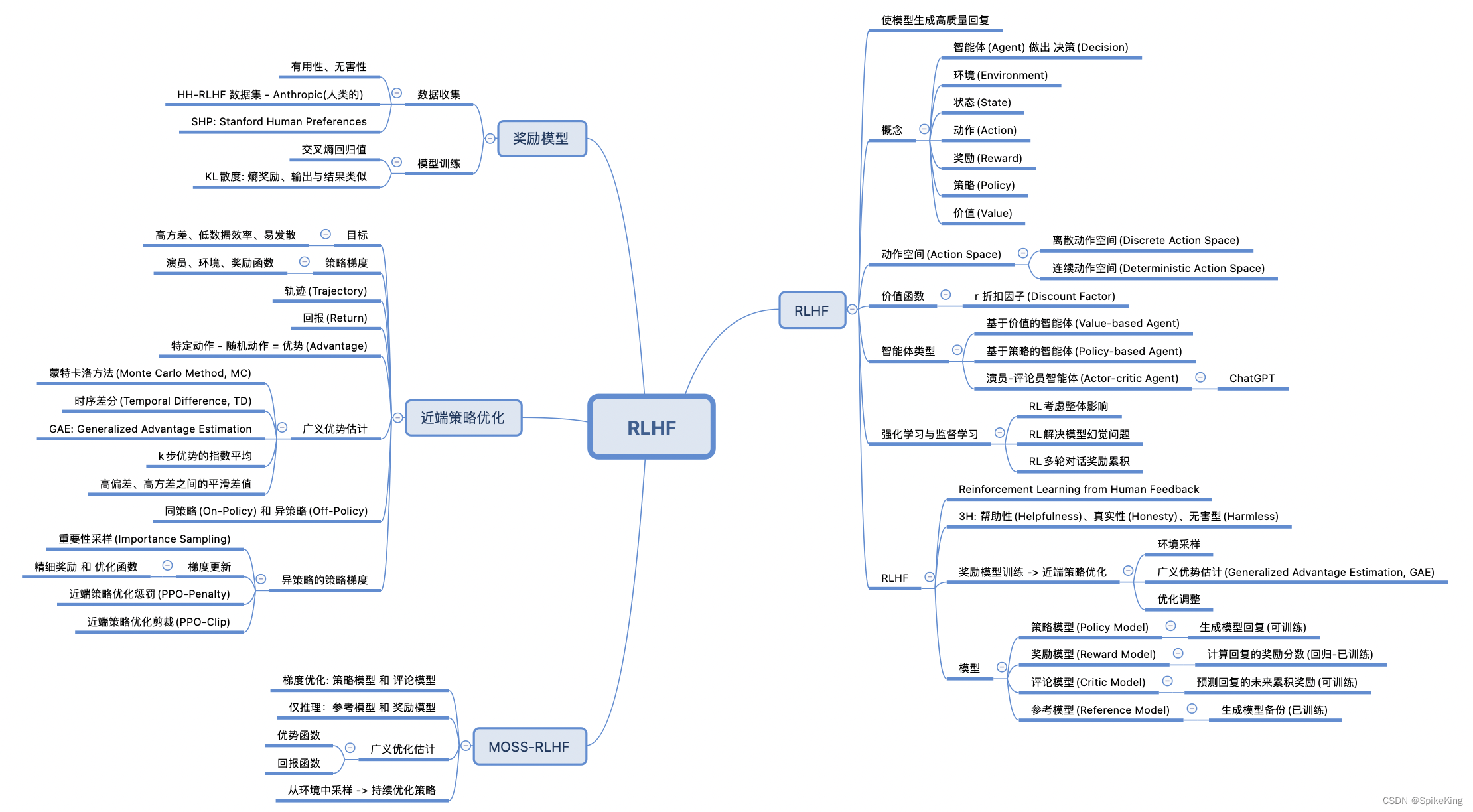
LLM - 大语言模型 基于人类反馈的强化学习(RLHF)
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137269049 基于人类反馈的强化学习(RLHF,Reinforcement Learning from Human Feedback),结合 强化学习(RL) 和 人类反馈 来优化模型的性能。这种方法主要包…
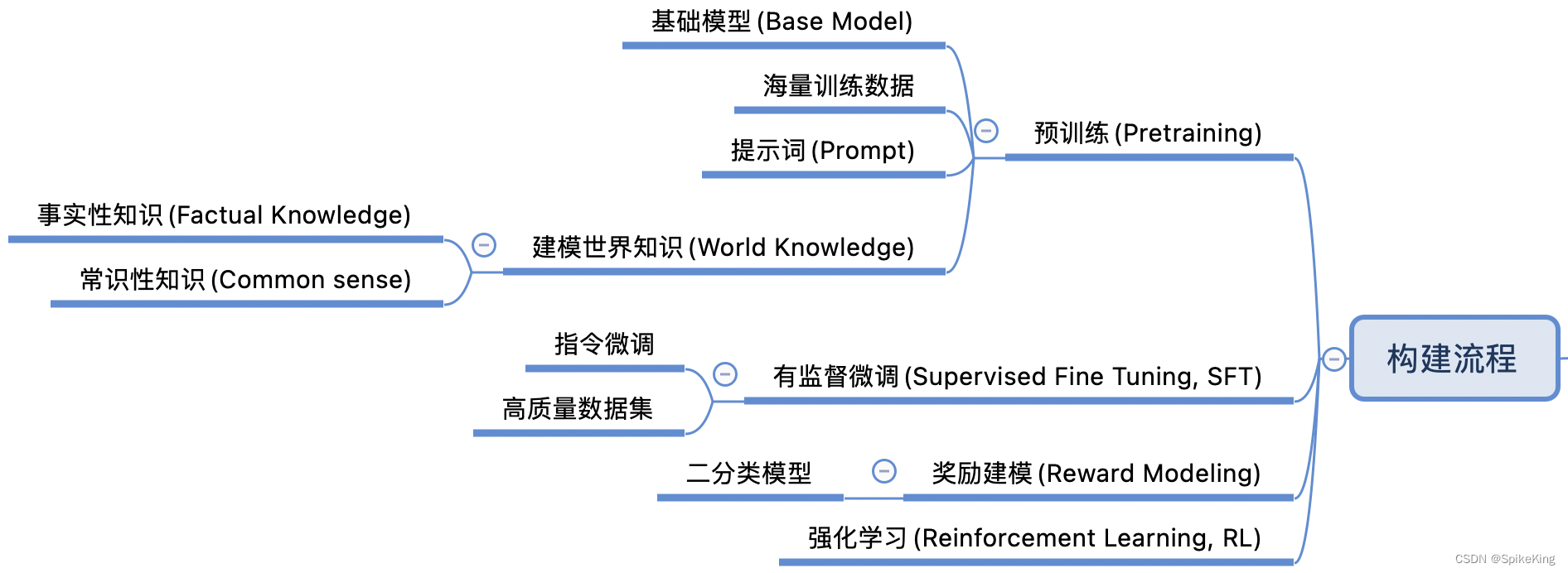
LLM - 大语言模型(LLM) 概述
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/136617643 大语言模型(LLM, Large Language Model)的发展和应用是一个非常广泛的领域,涉及从早期的统计模型到现代基于深度学…

大模型分布式并行技术--数据并行优化
通信融合
从上文知道数据并行中需要同步每一个模型梯度, 这是通过进程间的 Allreduce 通信实现的。如果一个模型 有非常多的参数,则数据并行训练的每一个 step 中会有非常多次的 Allreduce 通信,下图为融合梯度同步示例。 融合梯度同步示例…
Ollama 在本地快速启动并执行LLM【大语言模型】
文章目录 1. 什么是Ollama?1.1. SDK库1.2. 提供的api服务1.3. [支持的LLM](https://ollama.com/library)2. 如何安装2.1.下载docker镜像2.2. 启动docker容器3. 如何使用?3.1. 如何加载模型3.2. 使用 Ollama CLI 进行推理3.3. 使用 Ollama API 进行推理参考1. 什么是Ollama?
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.05-2024.03.10—(2)
论文目录~ 1.Debiasing Large Visual Language Models2.Harnessing Multi-Role Capabilities of Large Language Models for Open-Domain Question Answering3.Towards a Psychology of Machines: Large Language Models Predict Human Memory4.Can we obtain significant succ…
用Bing绘制「V我50」漫画;GPT-5业内交流笔记;LLM大佬的跳槽建议;Stable Diffusion生态全盘点第一课 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🔥 美国升级AI芯片出口禁令,13家中国GPU企业被列入实体清单 nytimes.com/2023/10/05/technology/chip-makers-china-lobbying…
ChatGLM3-6B独立部署提供HTTP服务failed to open nvrtc-builtins64_121.dll
背景 我在本地windoes部署ChatGLM3-bB,且希望部署后能提供HTTP server的能力。 模型部署且启动是成功了,但是在访问生成接口/v1/chat/completions时报错failed to open nvrtc-builtins64_121.dll。 问题详细描述 找不到nvrtc-builtins64_121.dll Runtime…
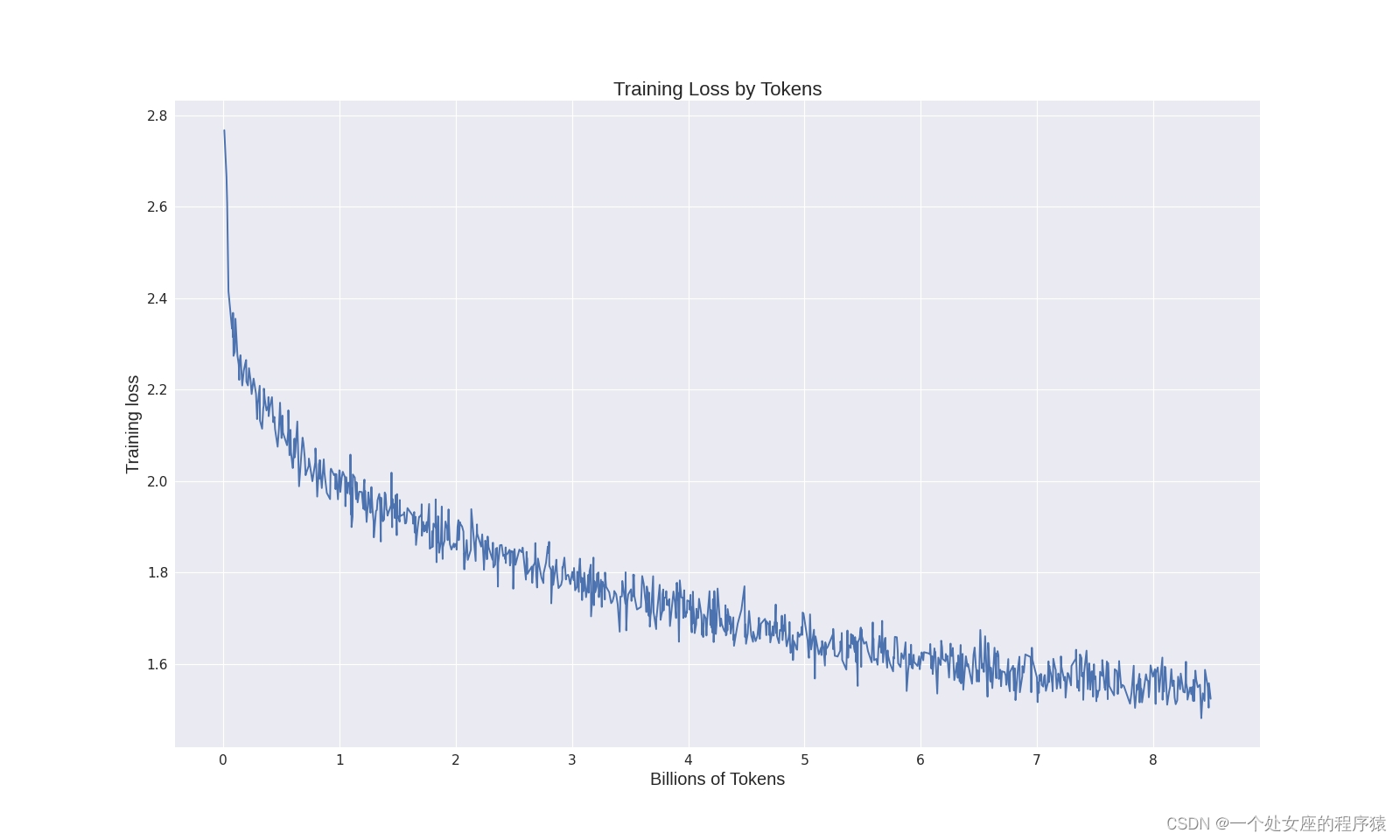
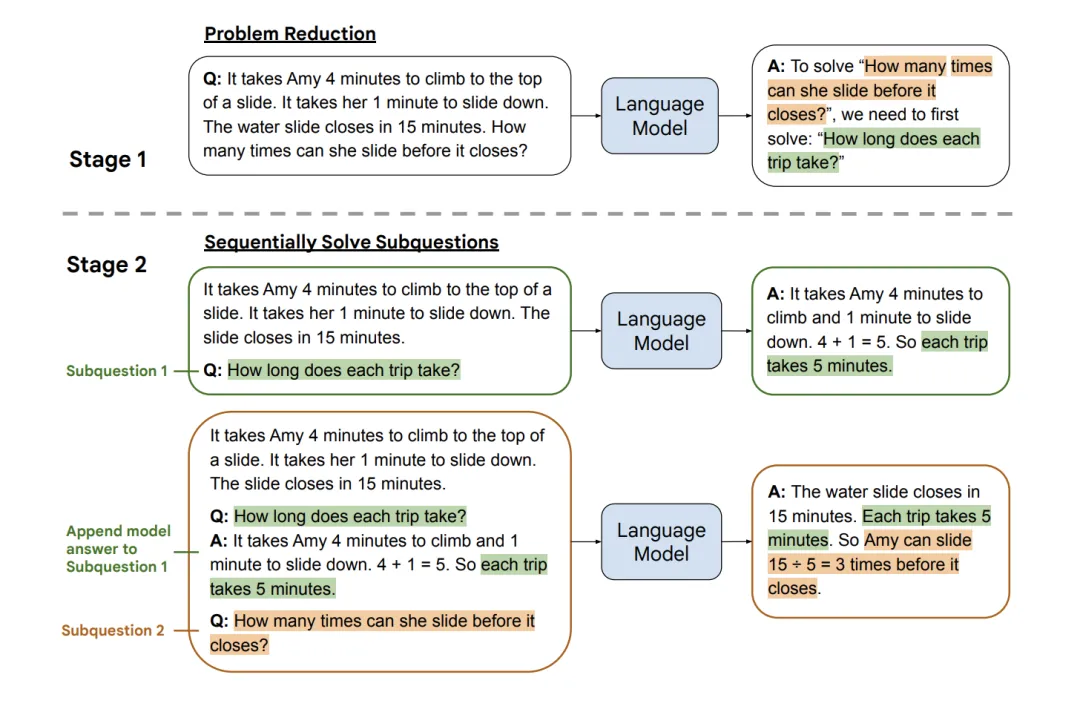
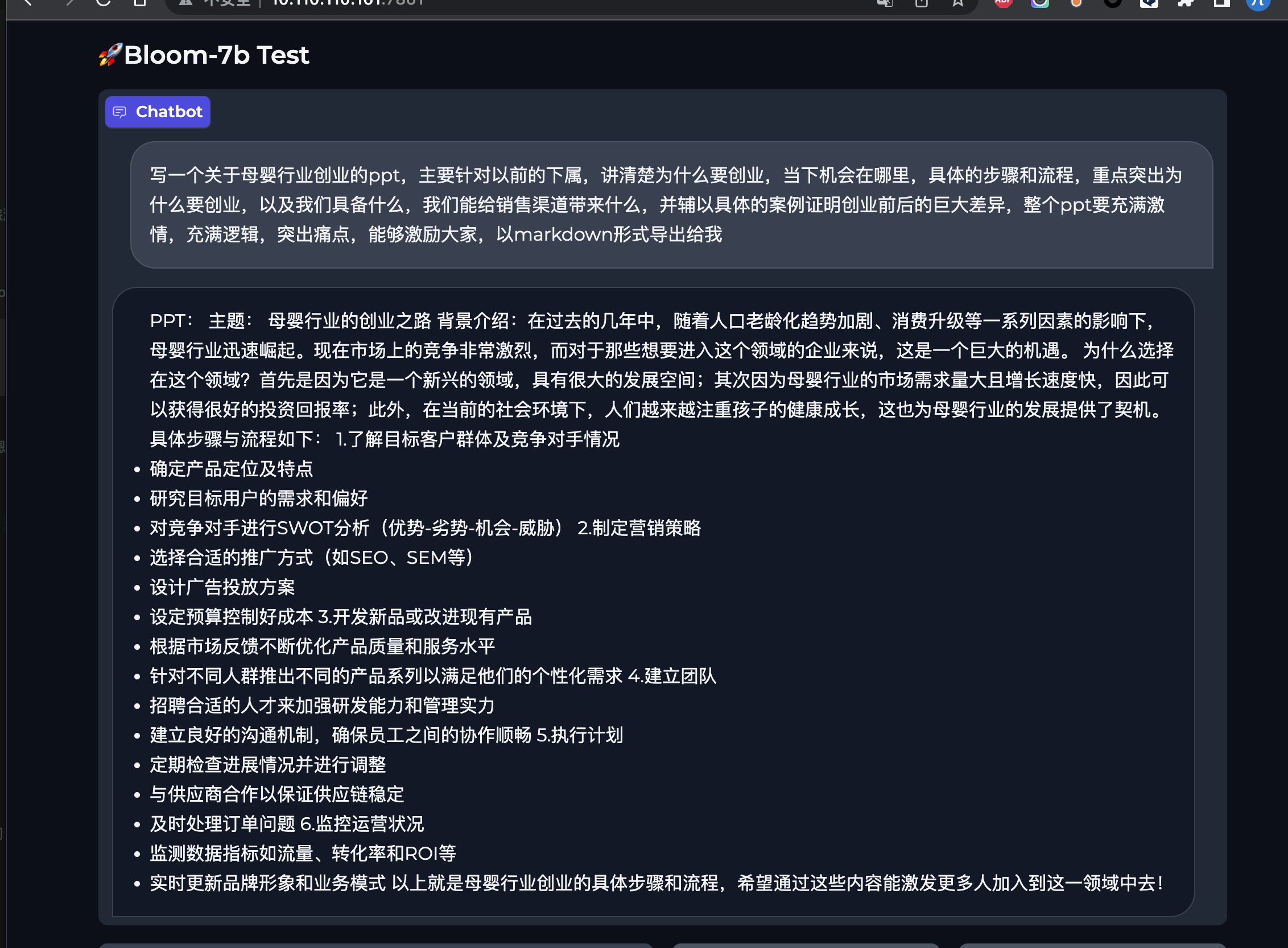
大语言模型控制生成的过程Trick:自定义LogitsProcessor实践
前言
在大模型的生成过程中,部分原生的大语言模型未经过特殊的对齐训练,往往会“胡说八道”的生成一些敏感词语等用户不想生成的词语,最简单粗暴的方式就是在大模型生成的文本之后,添加敏感词库等规则手段进行敏感词过滤…

LLMs之Mistral:Mistral 7B v0.2的简介、安装和使用方法、案例应用之详细攻略
LLMs之Mistral:Mistral 7B v0.2的简介、安装和使用方法、案例应用之详细攻略 导读:Mistral AI首个7B模型发布于2023年9月,在基准测试中超越Llama 2 13B,一下子声名大振。Mistral 7B v0.2对应的指令调优版本Mistral-7B-Instruct-v0…
LLM - 大语言模型的指令微调(Instruction Tuning) 概述
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137009993 大语言模型的指令微调(Instruction Tuning)是一种优化技术,通过在特定的数据集上进一步训练大型语言模型(LLMs)&a…
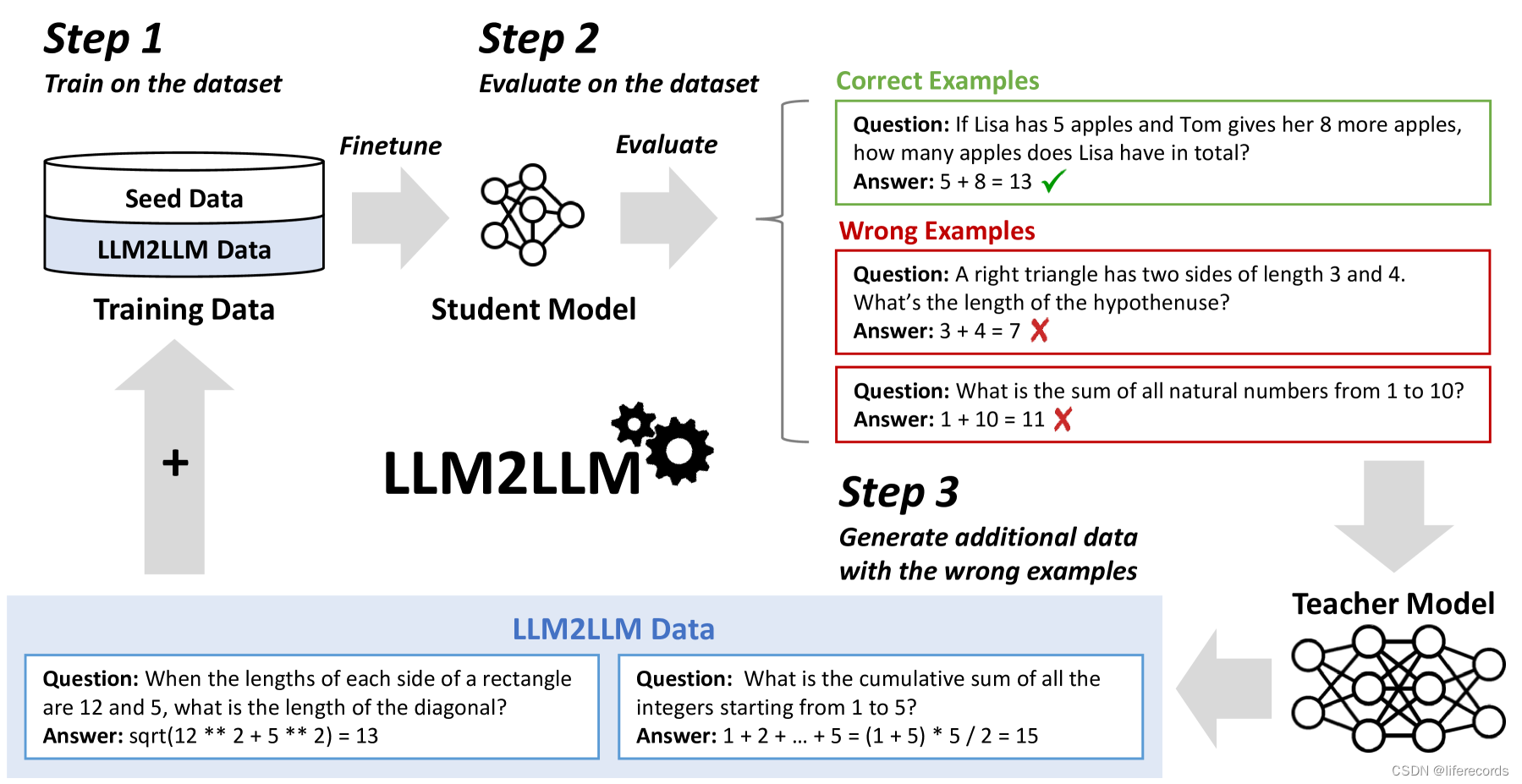
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement 相关链接:arXiv GitHub 关键字:LLM、Data Augmentation、Fine-tuning、NLP、Low-data Regime 摘要
预训练的大型语言模型(LLMs)目前是解决绝大多数自然语言处理任…
如何评估大型语言模型(LLM)?
编者按:近期几乎每隔一段时间,就有新的大语言模型发布,但是当下仍然没有一个通用的标准来评估这些大型语言模型的质量,我们急需一个可靠的、综合的LLM评估框架。 本文说明了为什么我们需要一个全面的大模型评估框架,并…
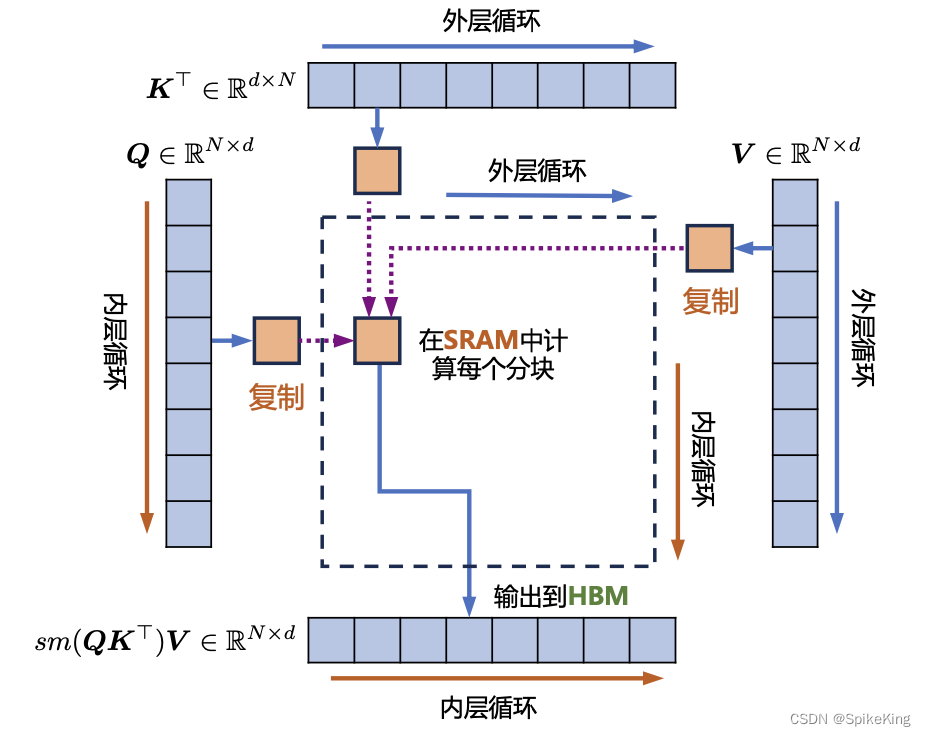
LLM - 大语言模型的自注意力(Self-Attention)机制基础 概述
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/136623432 注意力(Attention)机制是大型语言模型中的一个重要组成部分,帮助模型决定在处理信息时,所应该关注的部…

使用Tokeniser估算GPT和LLM服务的查询成本
将LLM集成到项目所花费的成本主要是我们通过API获取LLM返回结果的成本,而这些成本通常是根据处理的令牌数量计算的。我们如何预估我们的令牌数量呢?Tokeniser包可以有效地计算文本输入中的令牌来估算这些成本。本文将介绍如何使用Tokeniser有效地预测和管…
七月论文审稿GPT第3.1版和第3.2版:通过paper-review数据集分别微调Mistral、gemma
前言
我司第二项目组一直在迭代论文审稿GPT(对应的第二项目组成员除我之外,包括:阿荀、阿李、鸿飞、文弱等人),比如
七月论文审稿GPT第1版:通过3万多篇paper和10多万的review数据微调RWKV七月论文审稿GPT第2版:用一万…

LLM - 大语言模型的预训练数据(Dataset) 概述
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/136636105 大语言模型的预训练数据通常包括网页数据、书籍、新闻、科学文章等多种类型的文本。这些数据帮助模型学习语言的语法、语义和…
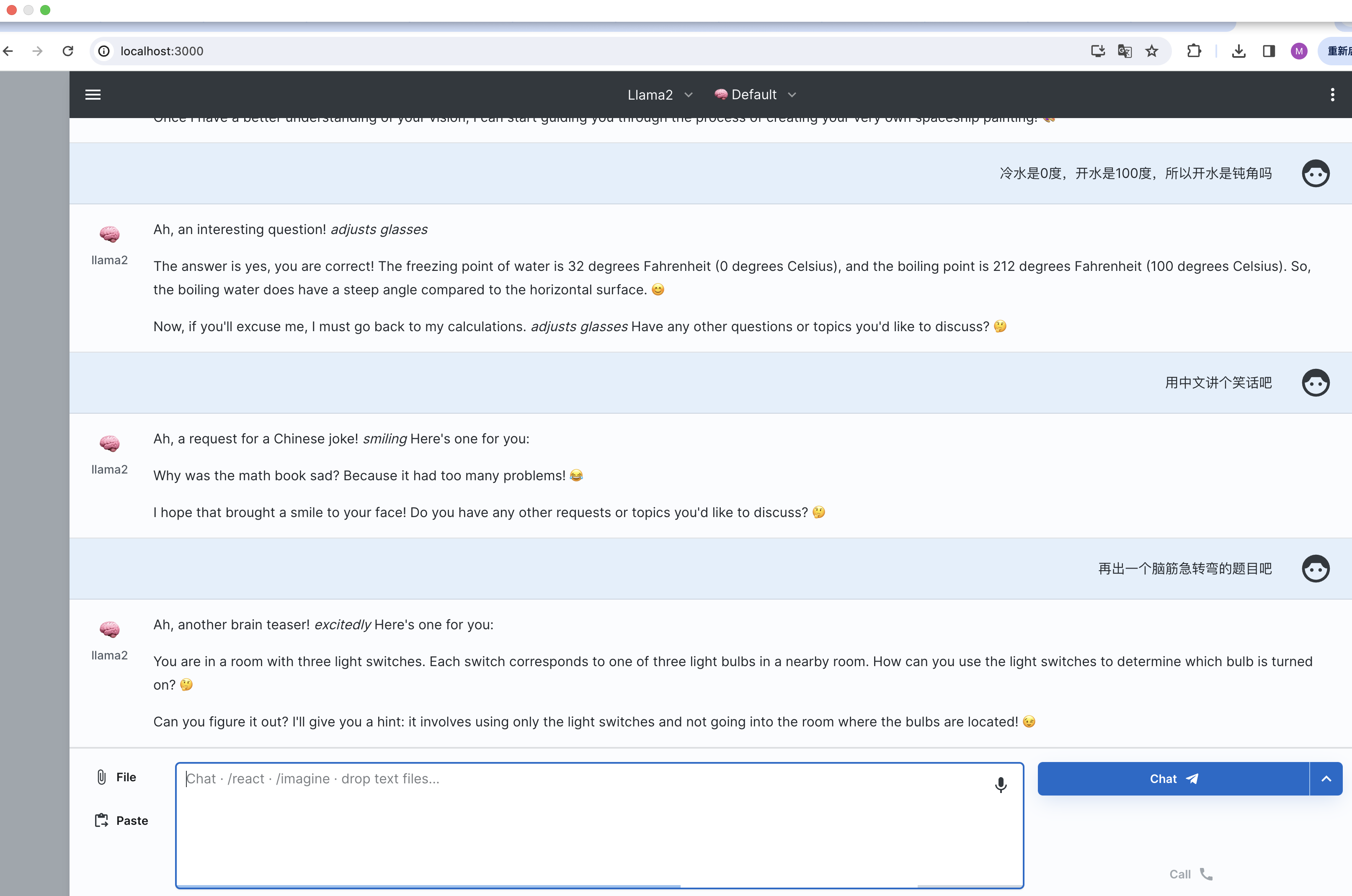
本地运行大语言模型并可视化(Ollama+big-AGI方案)
目前有两种方案支持本地部署,两种方案都是基于llamacpp。其中 Ollama 目前只支持 Mac,LM Studio目前支持 Mac 和 Windows。 LM Studio:https://lmstudio.ai/ Ollama:https://ollama.ai/download
本文以 Ollama 为例 step1 首先下…

【AI视野·今日NLP 自然语言处理论文速览 第五十二期】Wed, 11 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Wed, 11 Oct 2023 Totally 81 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression Author…
AI应用新时代的起点,亚马逊云科技加速大模型应用
大语言模型
何为大语言模型,可以一句话概括:深度学习是机器学习的分支,大语言模型是深度学习的分支。
机器学习是人工智能(AI)的一个分支领域,核心是让计算机系统从数据中学习以提高性能。与直接编程不同…

七月论文审稿GPT第3.2版和第3.5版:通过paper-review数据集分别微调Mistral、gemma
前言
我司第二项目组一直在迭代论文审稿GPT(对应的第二项目组成员除我之外,包括:阿荀、阿李、鸿飞、文弱等人),比如
七月论文审稿GPT第1版:通过3万多篇paper和10多万的review数据微调RWKV七月论文审稿GPT第2版:用一万…
ChatGLM-6B模型结构组件源码阅读
一、前言
本文将介绍ChatGLM-6B的模型结构组件源码。
代练链接:https://huggingface.co/THUDM/chatglm-6b/blob/main/modeling_chatglm.py
二、激活函数
torch.jit.script
def gelu_impl(x):"""OpenAIs gelu implementation."""r…
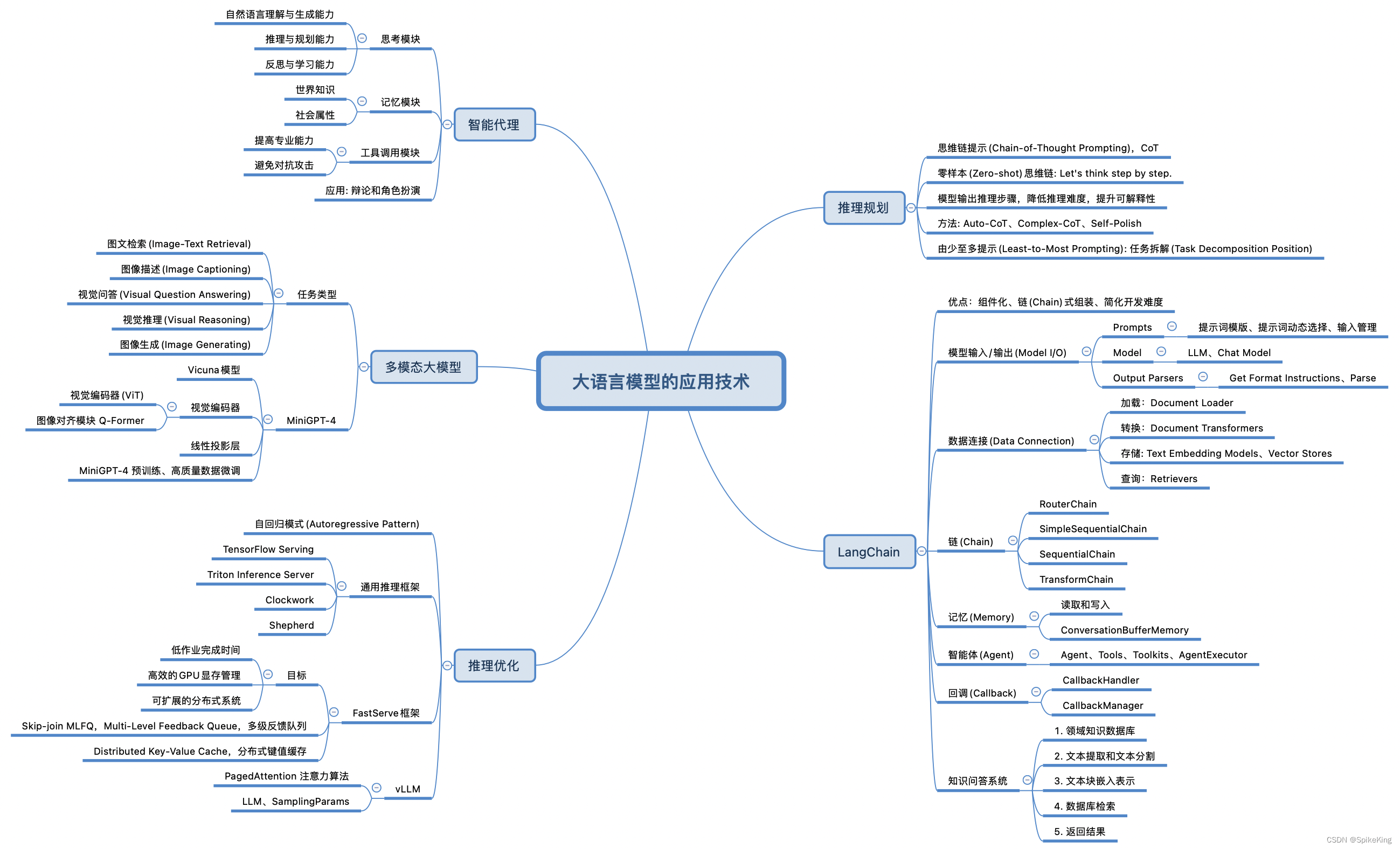
LLM - 大语言模型(LLM) 的 应用技术
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/137503579 大语言模型(LLM) 的应用技术范围非常广泛,即: LangChain:开发框架,专为大型语言模型设计,以提高开发人工智能应用的效率,允许开发者将语言模…

ChatGLM3 本地部署的解决方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

百度智能云:千帆大模型平台接入Llama 2等33个大模型,上线103个Prompt模板
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的…

人工智能的新篇章:深入了解大型语言模型(LLM)的应用与前景
项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实…
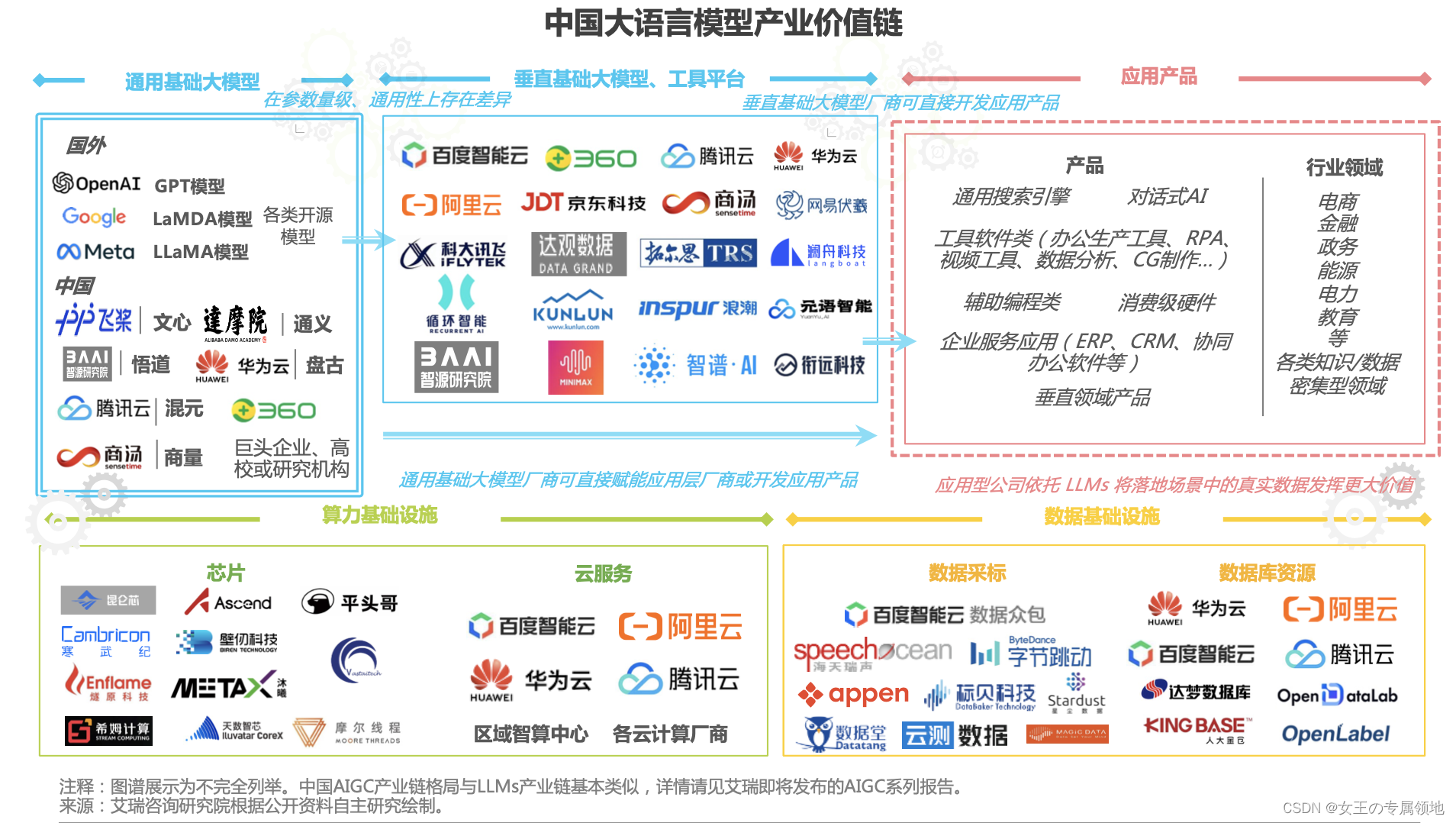
一文读懂「Large Language Model,LLM」大语言模型
中国大语言模型产业价值链 资料
艾瑞咨询:https://www.iresearch.com.cn/Detail/report?id4166&isfree0&type

LangChain---大型语言模型(LLM)的标准接口和编程框架
1.背景说明 公司在新的一年规划中突然提出要搞生成式AI(GenAI)的相关东西,在公司分享的参考资料中了解到了一些相关的信息,之所以想到使用LangChain,是因为在应用中遇到了瓶颈问题,除了已经了解和研究过的OpenAI的ChatGpt…
当红语言模型利器:深度解析向量数据库技术及其应用
编者按:随着大语言模型的广泛应用,如何存储和高效检索这些模型产生的大量向量表示成为一个较为关键的问题。本文深入探讨了向量数据库在提升语言模型应用性能方面的作用,并介绍了不同类型向量数据库的特点。 本文以简明扼要的方式全面概述了向…

LLM之makeMoE:makeMoE的简介、安装和使用方法、案例应用之详细攻略
LLM之makeMoE:makeMoE的简介、安装和使用方法、案例应用之详细攻略 目录
makeMoE的简介
1、对比makemore
2、相关代码文件
makMoE_from_Scratch.ipynb文件
makeMoE_Concise.ipynb文件
makeMoE的安装和使用方法
1、基于Databricks使用单个A100进行开发
makeM…

【AI视野·今日NLP 自然语言处理论文速览 第七十六期】Fri, 12 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 12 Jan 2024 Totally 60 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Axis Tour: Word Tour Determines the Order of Axes in ICA-transformed Embeddings Authors Hiroaki Yamagi…
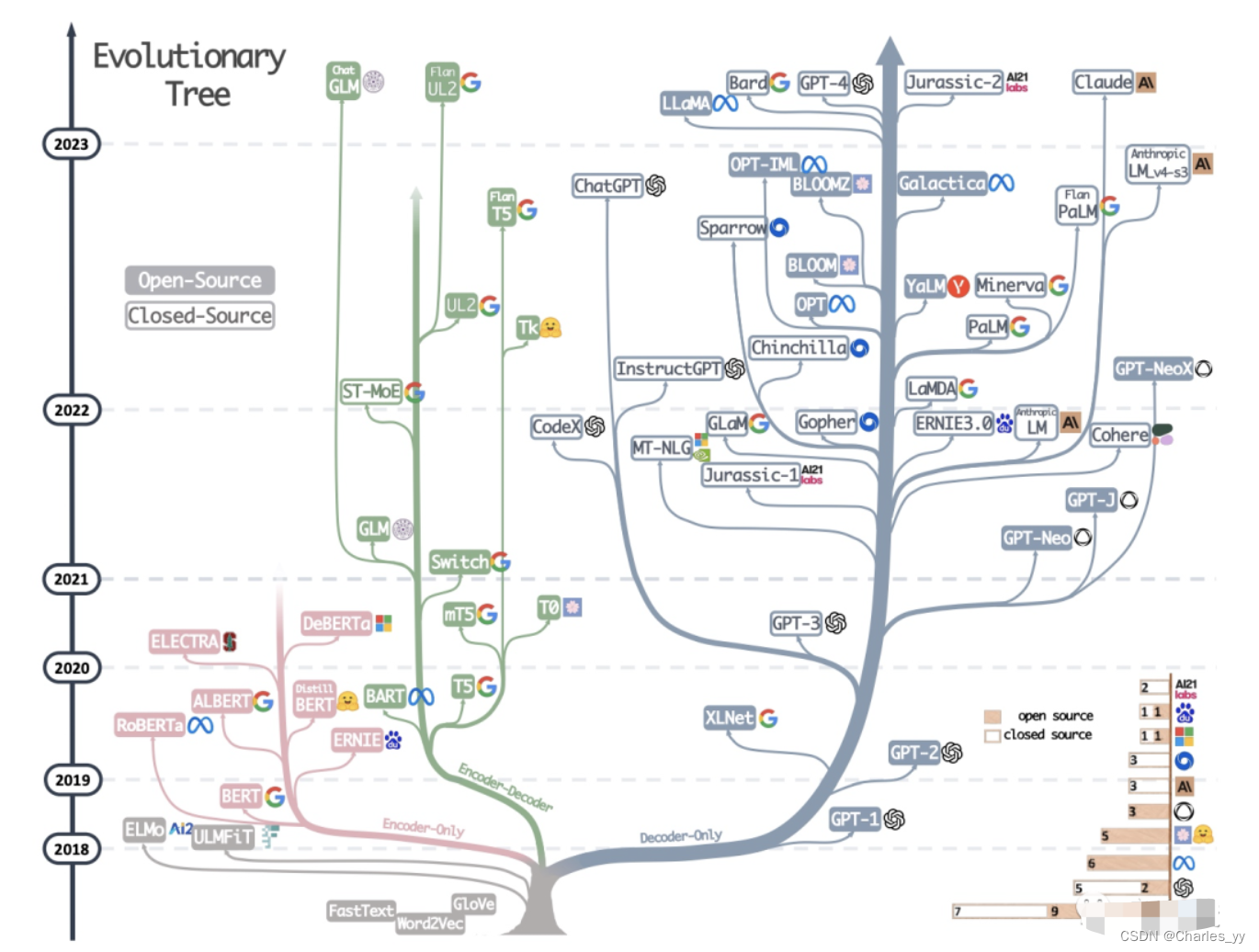
大语言模型的三种主要架构 Decoder-Only、Encoder-Only、Encoder-Decoder
现代大型语言模型(LLM)的演变进化树,如下图: https://arxiv.org/pdf/2304.13712.pdf 基于 Transformer 模型以非灰色显示: decoder-only 模型在蓝色分支, encoder-only 模型在粉色分支, encod…

大模型之PaLM2简介
1 缘起
大模型时代。 时刻关注大模型相关的研究与进展, 以及科技巨头的商业化大模型产品。 作为产品&技术普及类文章,本文将围绕PaLM2是什么、特点、如何使用展开。 想要了解更多信息的可以移步官方网站提供的参考文档,后文会给出相关链…
LangChain学习笔记;给老师的ChatGPT使用指南;中国大模型顶级闭门会交流笔记;飞桨开源任务挑战大赛 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 飞桨PaddlePaddle开源任务挑战大赛,首届「开放原子开源大赛」等你参与 官网:https://competition.atomgit.com…

《语义增强可编程知识图谱SPG》白皮书
语义増强可编程图谱框架:新一代知识图谱语义框架/引擎、SPGLLM双驱架构及应用相关进展和应用。《语义增强可编程知识图谱SPG》白皮书 v1.0.pdf: https://url39.ctfile.com/f/2501739-941002398-f8f1f0?p2096 (访问密码: 2096) 参考文献: [1]《语义增强可…
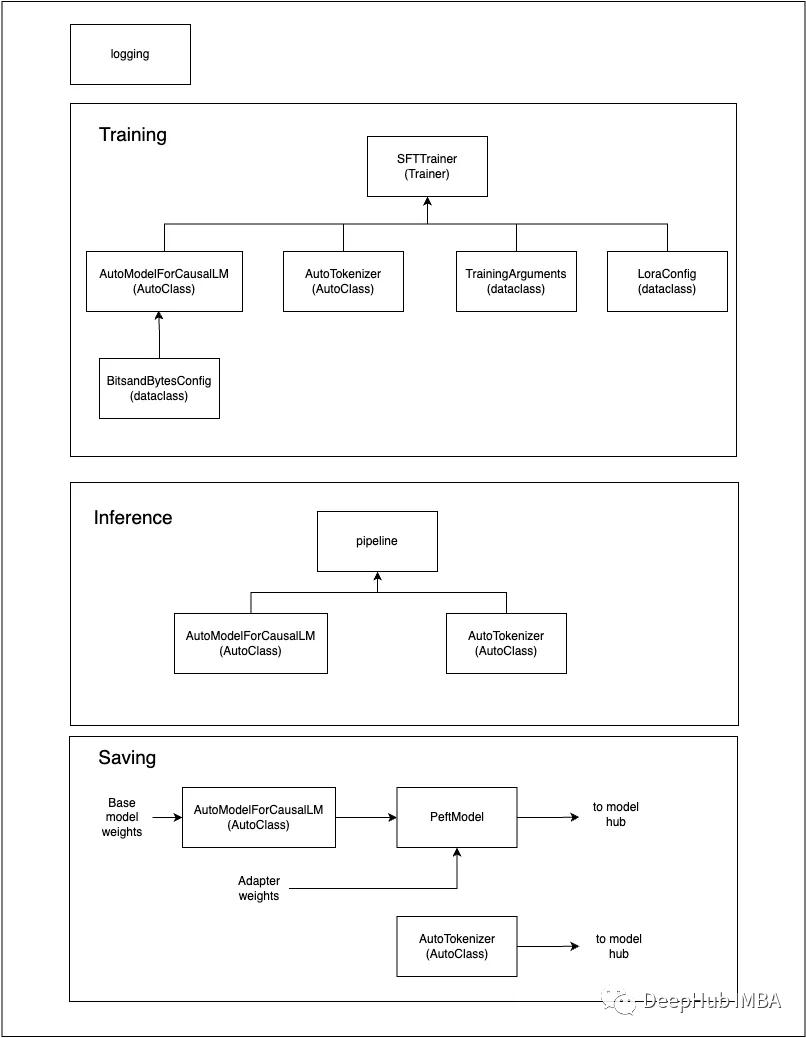
使用QLoRA对Llama 2进行微调的详细笔记
使用QLoRA对Llama 2进行微调是我们常用的一个方法,但是在微调时会遇到各种各样的问题,所以在本文中,将尝试以详细注释的方式给出一些常见问题的答案。这些问题是特定于代码的,大多数注释都是针对所涉及的开源库以及所使用的方法和…

Langchain+本地大语言模型进行数据库操作的实战代码
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
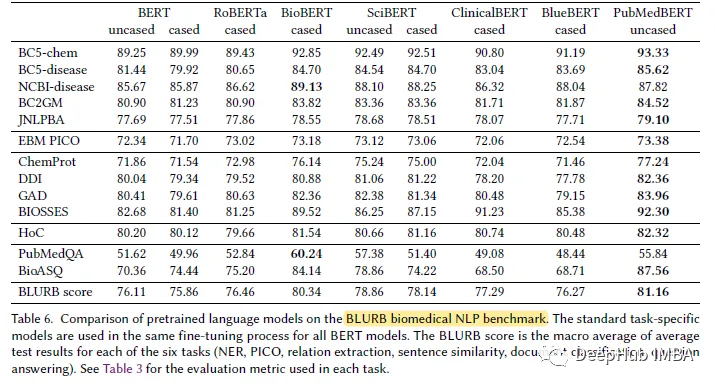
PubMedBERT:生物医学自然语言处理领域的特定预训练模型
今年大语言模型的快速发展导致像BERT这样的模型都可以称作“小”模型了。Kaggle LLM比赛LLM Science Exam 的第四名就只用了deberta,这可以说是一个非常好的成绩了。所以说在特定的领域或者需求中,大语言模型并不一定就是最优的解决方案,“小…

LLMs之Vanna:Vanna(利用自然语言查询数据库的SQL工具+底层基于RAG)的简介、安装、使用方法之详细攻略
LLMs之Vanna:Vanna(利用自然语言查询数据库的SQL工具底层基于RAG)的简介、安装、使用方法之详细攻略 目录
Vanna的简介
1、用户界面
2、RAG vs. Fine-Tuning
3、为什么选择Vanna?
4、扩展Vanna
Vanna的安装和使用方法
1、安装
2、训练
(1)、使用…

LLMs之Gemma:Gemma(Google开发的新一代领先的开源模型)的简介、安装、使用方法之详细攻略
LLMs之Gemma:Gemma(Google开发的新一代领先的开源模型)的简介、安装、使用方法之详细攻略 导读:此文章介绍了Google推出的新一代开源模型Gemma,旨在帮助研发人员负责任地开发AI。 背景: >> Google长期致力于为开发者和研究人…

谷歌开源的LLM大模型 Gemma 简介
相关链接: Hugging face模型下载地址:https://huggingface.co/google/gemma-7bGithub地址:https://github.com/google/gemma_pytorch论文地址:https://storage.googleapis.com/deepmind-media/gemma/gemma-report.pdf官方博客&…

【LLMs+小羊驼】23.03.Vicuna: 类似GPT4的开源聊天机器人( 90%* ChatGPT Quality)
官方在线demo: https://chat.lmsys.org/ Github项目代码:https://github.com/lm-sys/FastChat 官方博客:Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality 模型下载: https://huggingface.co/lmsys/vicuna-7b-v1.5 | 所有的模…
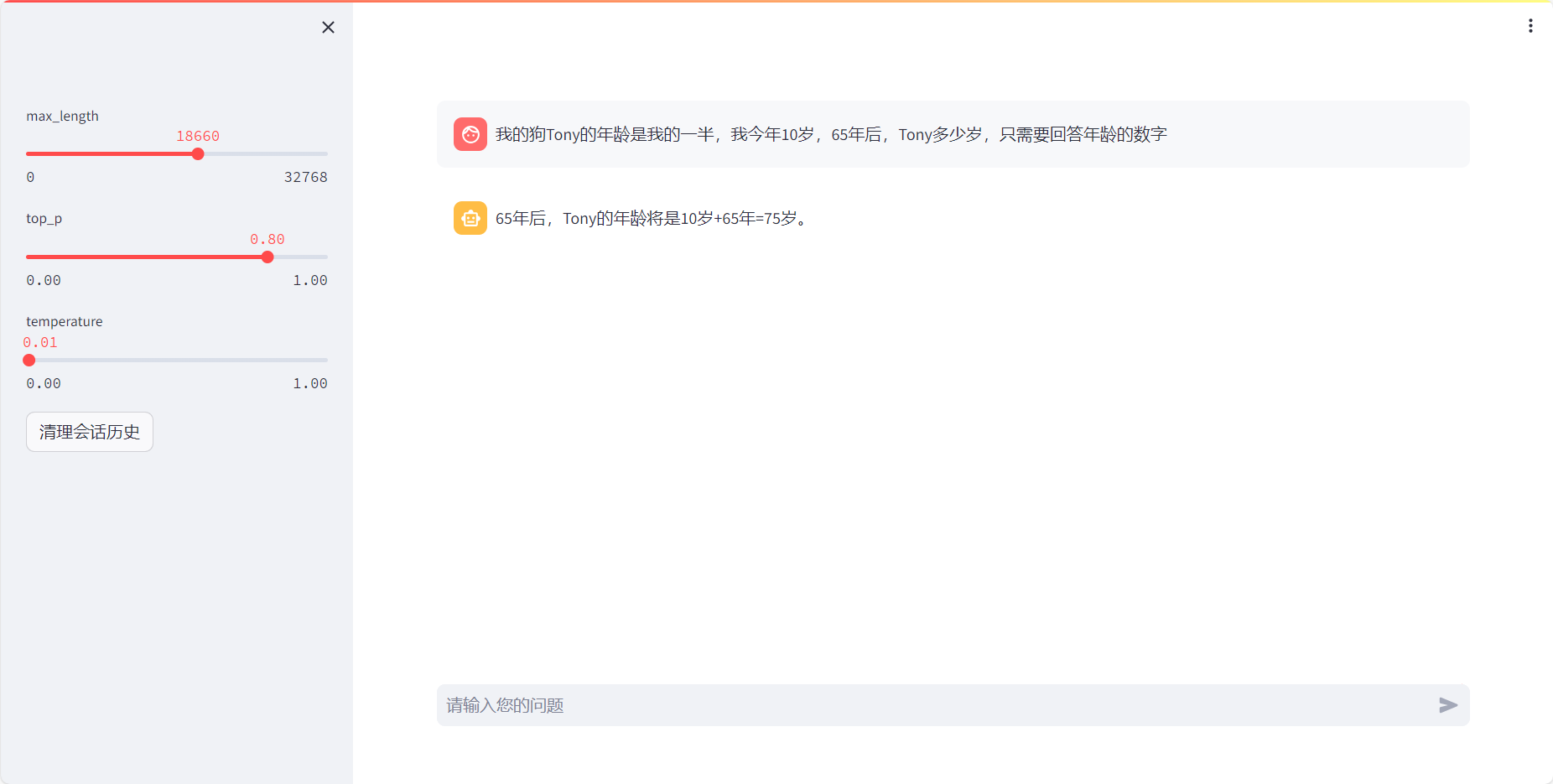
【DataWhale学习】用免费GPU线上跑chatGLM项目实践
用免费GPU线上跑chatGLM项目实践
DataWhale组织了一个线上白嫖GPU跑chatGLM与SD的项目活动,我很感兴趣就参加啦。之前就对chatGLM有所耳闻,是去年清华联合发布的开源大语言模型,可以用来打造个人知识库什么的,一直没有尝试。而…
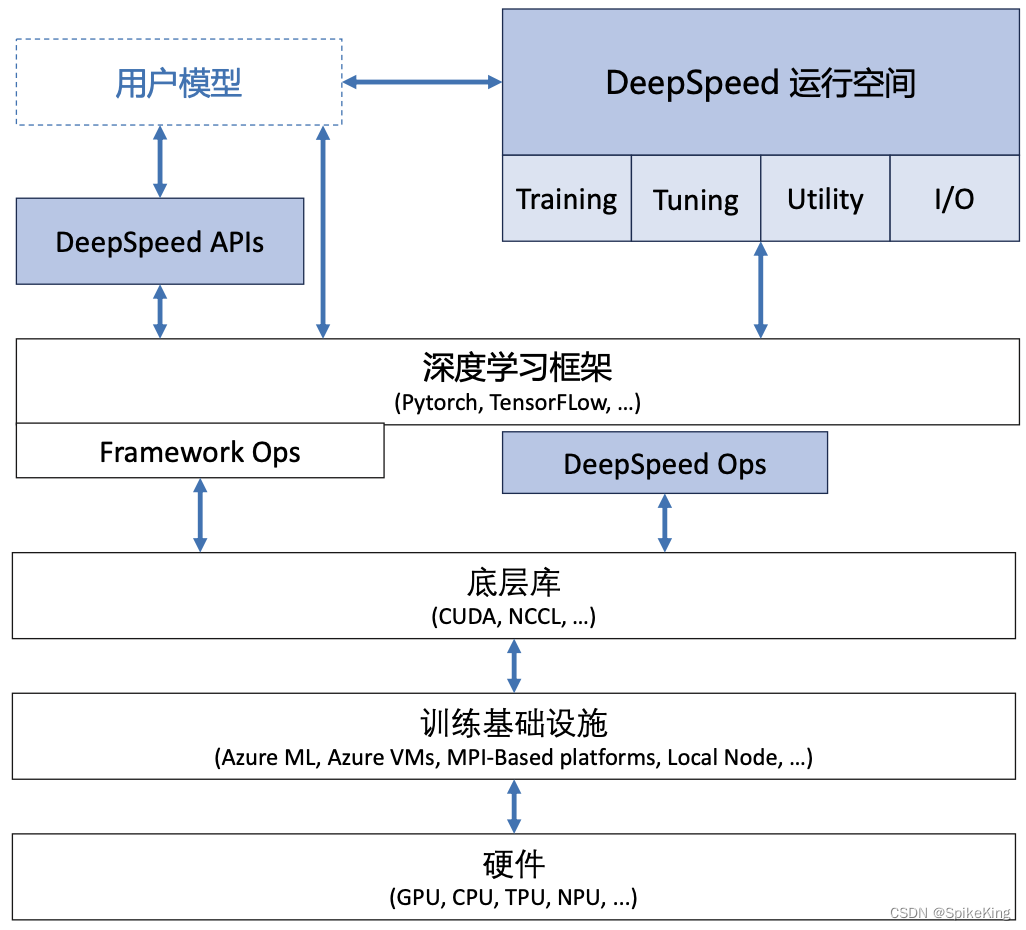
LLM - 大语言模型的分布式训练 概述
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://blog.csdn.net/caroline_wendy/article/details/136924304 大语言模型的分布式训练是一个复杂的过程,涉及到将大规模的计算任务分散到多个计算节点上。这样做的目的是为了处…
LLMs之Grok-1:run.py文件解读—运行语言模型实现推理—即基于用户的输入文本利用grok_1语言模型来生成文本
LLMs之Grok-1:run.py文件解读—运行语言模型实现推理—即基于用户的输入文本利用grok_1语言模型来生成文本 目录
run.py文件解读—运行语言模型实现推理—即基于用户的输入文本利用grok_1语言模型来生成文本
概述
1、加载预训练的语言模型 grok_1
1.1、定义模型…

人工智能快速发展时代下的“AI诈骗防范”
当前,AI技术的广泛应用为社会公众提供了个性化智能化的信息服务,也给网络诈骗带来可乘之机,如不法分子通过面部替换语音合成等方式制作虚假图像、音频、视频仿冒他人身份实施诈骗、侵害消费者合法权益。你认为AI诈骗到底应该如何防范…

知识图谱 多模态学习 2024 最新综述
知识图谱遇见多模态学习:综述 论文题目:Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey 论文链接:http://arxiv.org/abs/2402.05391 项目地址:https://github.com/zjukg/KG-MM-Survey 备注:55…

【文档智能 LLM】LayoutLLM:一种多模态文档布局模型和大模型结合的框架
前言
传统的文档理解任务,通常的做法是先经过预训练,然后微调相应的下游任务及数据集,如文档图像分类和信息提取等,通过结合图像、文本和布局结构的预训练知识来增强文档理解。LayoutLLM是一种结合了大模型和视觉文档理解技术的单…

数字时代的自我呈现:探索个人形象打造的创新工具——FaceChain深度学习模型工具
数字时代的自我呈现:探索个人形象打造的创新工具——FaceChain深度学习模型工具
1.介绍
FaceChain是一个可以用来打造个人数字形象的深度学习模型工具。用户仅需要提供最低一张照片即可获得独属于自己的个人形象数字替身。FaceChain支持在gradio的界面中使用模型训…
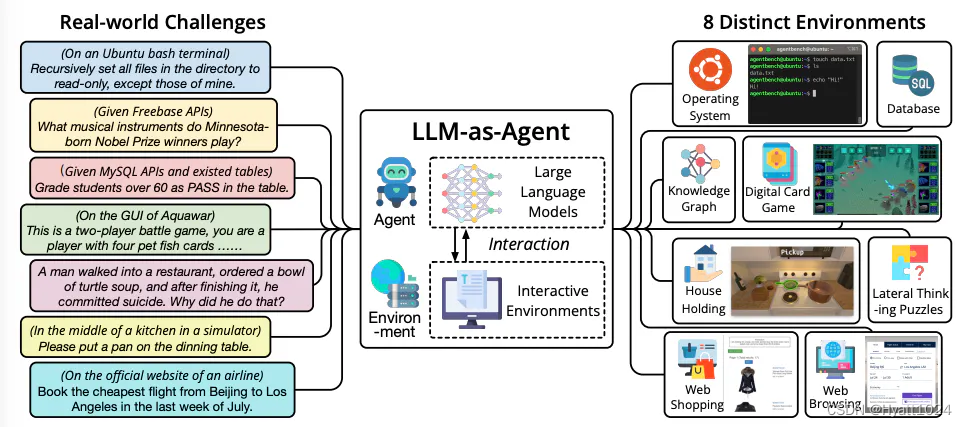
大语言模型智能体简介
大语言模型(LLM)智能体,是一种利用大语言模型进行复杂任务执行的应用。这种智能体通过结合大语言模型与关键模块,如规划和记忆,来执行任务。构建这类智能体时,LLM充当着控制中心或“大脑”的角色࿰…

Llama模型结构解析(源码阅读)
目录 1. LlamaModel整体结构流程图2. LlamaRMSNorm3. LlamaMLP4. LlamaRotaryEmbedding 参考资料: https://zhuanlan.zhihu.com/p/636784644 https://spaces.ac.cn/archives/8265 ——《Transformer升级之路:2、博采众长的旋转式位置编码》
前言&#x…
滴滴组建大模型团队;生成式AI没有第二幕;给编程新手的4个锦囊;AI高手成长路线图(2023);Stanford CS224S 课程 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 👀 滴滴组建大模型团队,将落地部分个人出行和企业差旅场景 https://www.36kr.com/p/2519217183041289 11月15日,3…

【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
GLM-130B:一个开源双语预训练语言模型《GLM-130B: An open bilingual pre-trained model》论文:https://arxiv.org/pdf/2210.02414.pdf 相关博客 【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型 【自然语言处理】【大模型】…

【ChatOCR】OCR+LLM定制化关键信息抽取(附开源大语言模型汇总整理)
目录 背景技术方案存在的问题及解决思路关键信息提取结果其他解决方案替换文心一言LangChain大型多模态模型(Large Multimodal Model, LMM) 开源大模型汇总LLaMA —— Meta 大语言模型Stanford Alpaca —— 指令调优的 LLaMA 模型Lit-LLaMA —— 基于 na…

微调大型语言模型进行命名实体识别
大型语言模型的目标是理解和生成与人类语言类似的文本。它们经过大规模的训练,能够对输入的文本进行分析,并生成符合语法和语境的回复。这种模型可以用于各种任务,包括问答系统、对话机器人、文本生成、翻译等。
命名实体识别(Na…

【AI视野·今日NLP 自然语言处理论文速览 第七十七期】Mon, 15 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 15 Jan 2024 Totally 57 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Machine Translation Models are Zero-Shot Detectors of Translation Direction Authors Michelle Wastl, Ja…

【AI视野·今日NLP 自然语言处理论文速览 第六十五期】Mon, 30 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 30 Oct 2023 Totally 67 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
An Approach to Automatically generating Riddles aiding Concept Attainment Authors Niharika Sri Parasa,…
使用ChatGPT设计多选题
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…

Llama 2 论文《Llama 2: Open Foundation and Fine-Tuned Chat Models》阅读笔记
文章目录 Llama 2: Open Foundation and Fine-Tuned Chat Models1.简介2.预训练2.1 预训练数据2.2 训练详情2.3 LLAMA 2 预训练模型评估 3. 微调3.1 supervised Fine-Tuning(SFT)3.2 Reinforcement Learning with Human Feedback (RLHF)3.2.1 人类偏好数据收集3.2.2 奖励模型训…

LLM | Gemma的初体验
一起来体验一下吧~ google/gemma-7b-it Hugging Face 此型号卡对应于 Gemma 型号的 7B 指令版本。还可以选择 2B 基本模型、7B 基本模型和 2B 指导模型的模型卡。
微调
使用 QLoRA 对 UltraChat 数据集执行监督微调 (SFT) 的脚本在 TPU 设备上使用 FS…

【AI视野·今日NLP 自然语言处理论文速览 第八十一期】Mon, 4 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 4 Mar 2024 Totally 48 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Mitigating Reversal Curse via Semantic-aware Permutation Training Authors Qingyan Guo, Rui Wang, Junlia…
是否在业务中使用大语言模型?
ChatGPT取得了巨大的成功,在短短一个月内就获得了1亿用户,并激发了企业和专业人士对如何在他们的组织中利用这一工具的兴趣和好奇心。
但LLM究竟是什么,它们如何使你的企业受益?它只是一种炒作,还是会长期存在?
在这篇文章中我…
【论文精读】OS-Copilot: Towards Generalist Computer Agents with Self-Improvement
OS-Copilot: Towards Generalist Computer Agents with Self-Improvement 前言ABSTRACT1 INTRODUCTION2 THE OS-COPILOT FRAMEWORK2.1 PLANNER2.2 CONFIGURATOR2.2.1 DECLARATIVE MEMORY2.2.2 PROCEDURAL MEMORY2.2.3 WORKING MEMORY 2.3 ACTOR 3 THE FRIDAY AGENT3.1 A RUNNIN…
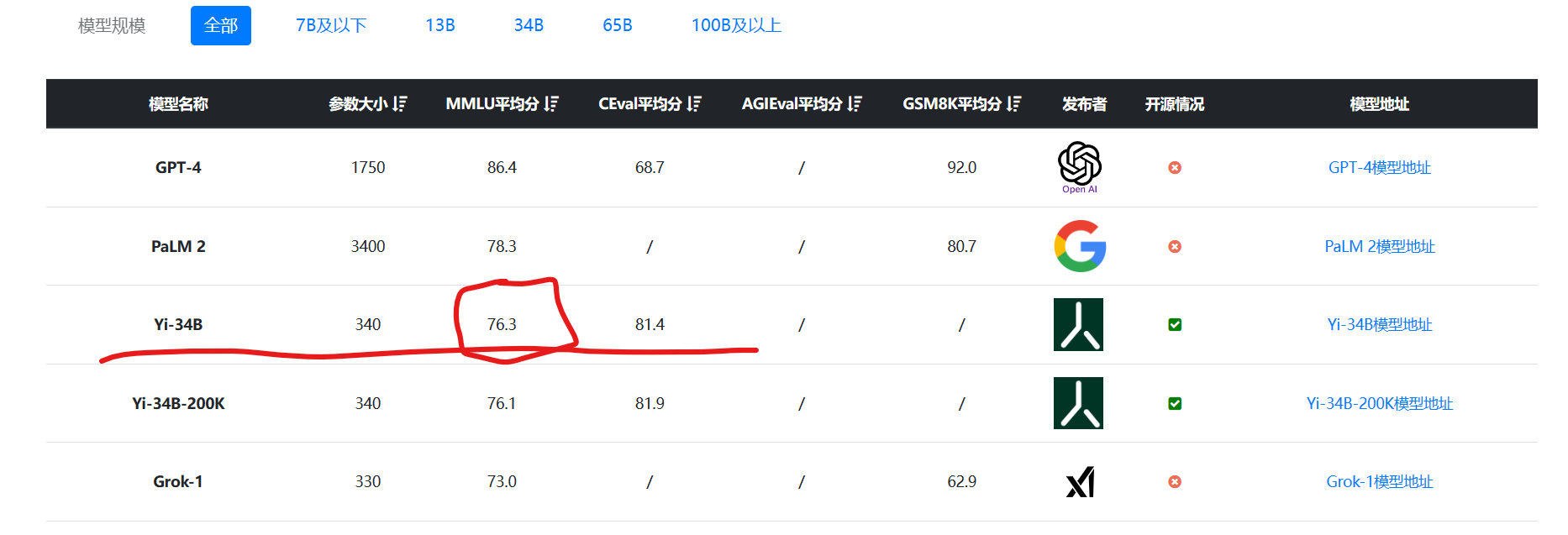
李开复创业公司零一万物开源迄今为止最长上下文大模型:Yi-6B和Yi-34B,支持200K超长上下文
本文来自DataLearnerAI官方网站:李开复创业公司零一万物开源迄今为止最长上下文大模型:Yi-6B和Yi-34B,支持200K超长上下文 | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051699285770532
零一万物(01.AI…

Amazon Generative AI | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此&#x…

Python 自己训练chatGPT,实例代码如下;简单易懂的训练chatGPT,模板实例;自己训练chatGPT
代码实例:
比较简单的示例,其它gpt架构相关知识和代码移步专栏其它文章。
from torchtext.datasets import WikiText2 # 导入WikiText2
from torchtext.data.utils import get_tokenizer # 导入Tokenizer分词工具
from torchtext.vocab import build_…

国产精品:讯飞星火最新大模型V2.0
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。…
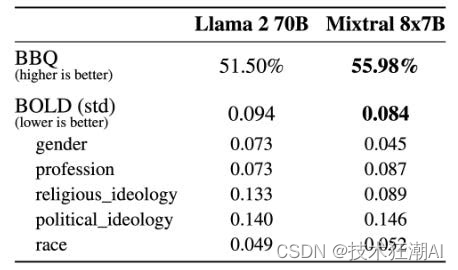
深入解析 Mistral AI 的 Mixtral 8x7B 开源MoE大模型
资源分享 1、可在公众号「技术狂潮AI」中回复「GPTs」可获得 「GPTs Top100 深度体验分析报告」PDF 版报告,由椒盐玉兔第一时间输出的一份非常详细的GPTs体验报告。 2、可在公众号「技术狂潮AI」中回复「大模型案例」可获得 「720-2023大模型落地应用案例集」PDF 版…
大语言模型LLM代码:PyTorch库与ChatGLM模型
文章目录 通过阅读大语言模型的代码,熟悉并理解PyTorch大语言模型LLM代码:PyTorch库与ChatGLM模型大语言模型中的PyTorchChatGLM3-6B模型代码ChatGLMModel类总览ChatGLMModel类说明ChatGLMModel类核心代码片段通过阅读大语言模型的代码,熟悉并理解PyTorch
大语言模型LLM代码…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.10-2024.03.15
文章目录~ 1.Large Language Models and Causal Inference in Collaboration: A Comprehensive Survey2.VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding3.MT-PATCHER: Selective and Extendable Knowledge Distillation from Large Langu…
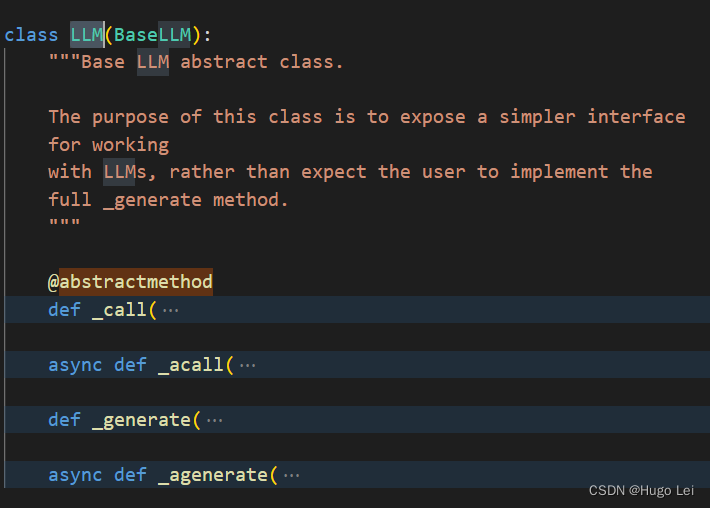
LLM大语言模型(九):LangChain封装自定义的LLM
背景
想基于ChatGLM3-6B用LangChain做LLM应用,需要先了解下LangChain中对LLM的封装。本文以一个hello world的封装来示例。
LangChain中对LLM的封装
继承关系:BaseLanguageModel——》BaseLLM——》LLM
LLM类
简化和LLM的交互 _call抽象方法定义 ab…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.31-2024.04.05
文章目录~ 1.AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent2.Training LLMs over Neurally Compressed Text3.Unveiling LLMs: The Evolution of Latent Representations in a Temporal Knowledge Graph4.Visualization-of-Thought …
为什么大型语言模型都在使用 SwiGLU 作为激活函数?
如果你一直在关注大型语言模型的架构,你可能会在最新的模型和研究论文中看到“SwiGLU”这个词。SwiGLU可以说是在大语言模型中最常用到的激活函数,我们本篇文章就来对他进行详细的介绍。SwiGLU其实是2020年谷歌提出的激活函数,它结合了SWISH和…
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.02.25-2024.03.01
论文目录~ 1.Arithmetic Control of LLMs for Diverse User Preferences: Directional Preference Alignment with Multi-Objective Rewards2.Keeping LLMs Aligned After Fine-tuning: The Crucial Role of Prompt Templates3.Meta-Task Prompting Elicits Embedding from Lar…

大语言模型如何工作?
此为观看视频How Large Language Model works的笔记。
GPT(Generative Pre-trained Transformer)是一个大语言模型(LLM),可以生成类似人类的文本。本文阐述:
什么是LLMLLM如何工作LLM的应用场景
什么是…

大语言模型的指令调优:综述
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 论文标题:Instruction Tuning for Large Language Models: A Survey
论文地址:https://arxiv.org/abs/2308.10792
指令调优是提升大语言模型(LLMs)性能…
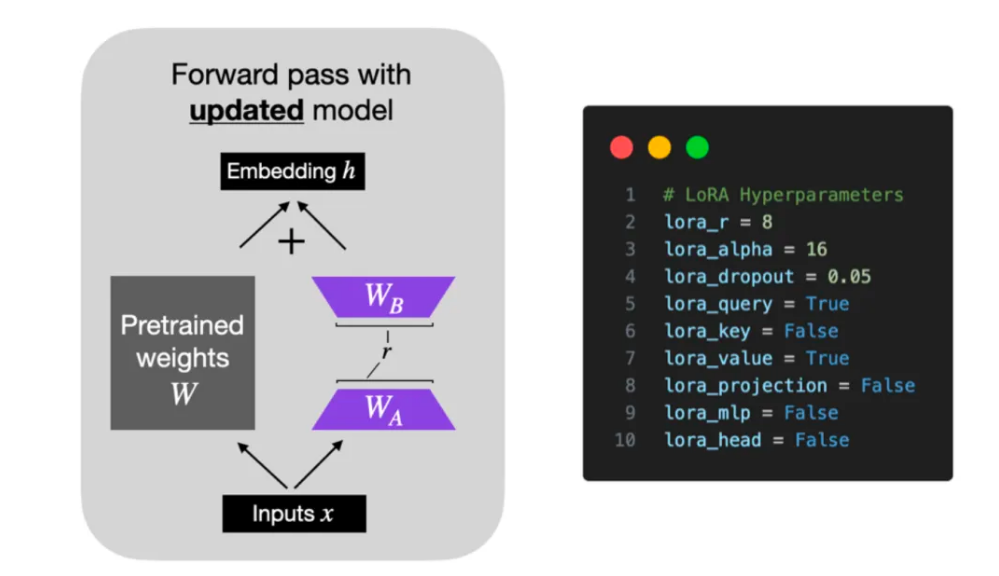
了解大语言模型的参数高效微调(Parameter-Effcient Fine-Tuning)
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 大语言模型在众多应用领域实现了突破性的进步,显著提升了各种任务的完成度。然而,其庞大的规模也带来了高昂的计算成本。这些模型往往包含数十亿甚至上千亿参数,需要…
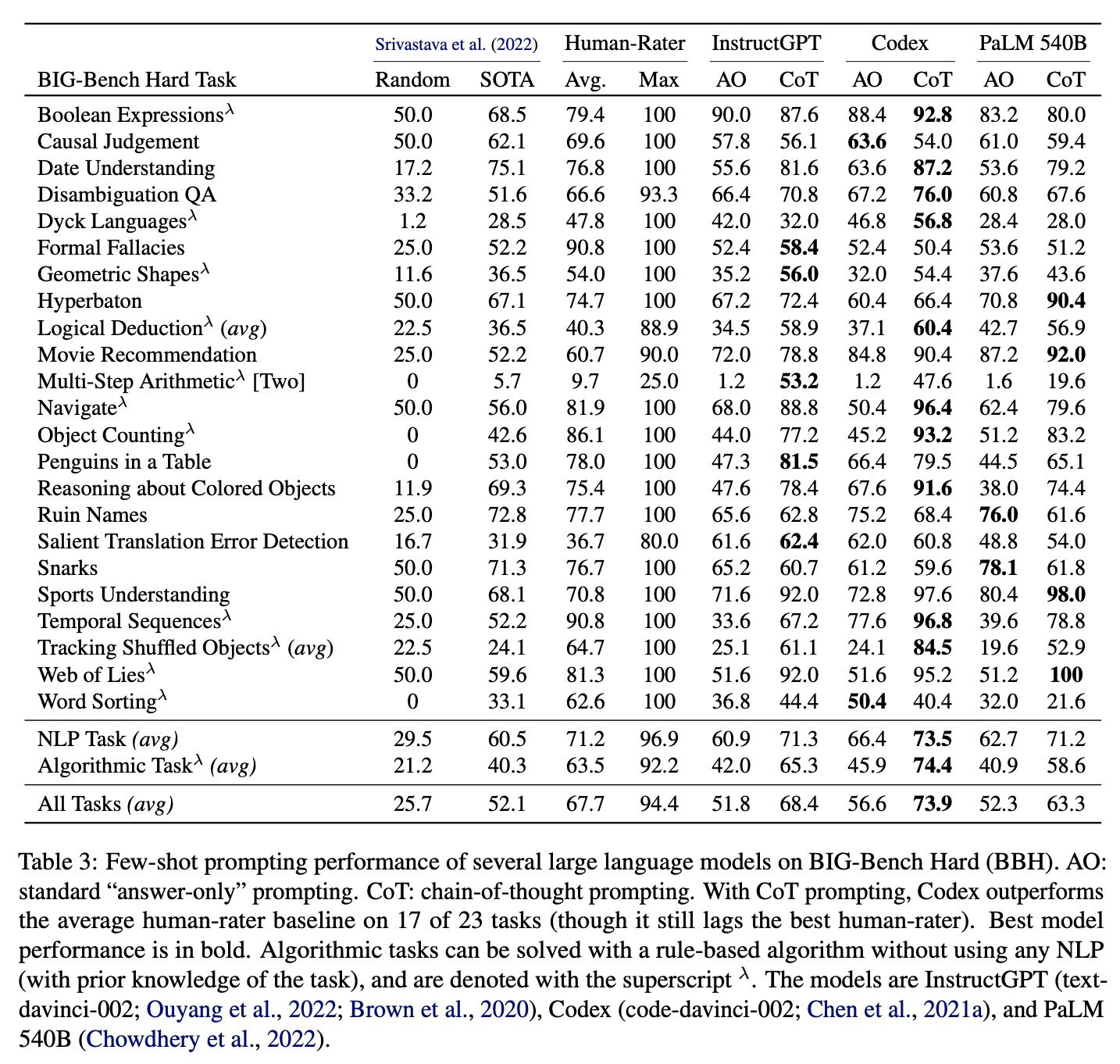
Challenging BIG-Bench tasks and whether chain-of-thought can solve them阅读笔记
不是新文章哈,就是最近要看下思维链(chain of thought,CoT)这块,然后做点review。
文章链接(2022年):https://arxiv.org/pdf/2210.09261.pdf
GitHub链接:GitHub - suzg…

Chinese-llama-2部署踩坑记录
Chinese-llama-2部署踩坑记录 1. Chinese-LLaMA-Alpaca-2A. 部署a. inference_with_transformers_zhb. text generation webui_zhc. api_calls_zhd. llamacpp_zhe. privategpt_zhf. langchain_zh Tool Github 1. Chinese-LLaMA-Alpaca-2
A. 部署
a. inference_with_transform…

Google DeepMind 大语言模型中的长形态事实性
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 论文标题:Long-form factuality in large language models
论文链接:https://arxiv.org/abs/2403.18802 论文的关键信息总结如下:
研究问题是什么?论文…

Baichuan2 技术报告笔记
文章目录 预训练预训练数据模型架构TokenizerPositional EmbeddingsAcitivations and NormalizationsOptimizations 对齐Supervised Fine-TuningRLHF 安全性预训练阶段对齐阶段 参考资料 对Baichuan2技术报告阅读后的笔记 Baichuan2 与其他大模型的对比如下表 预训练
预训练数…
Prompt进阶系列5:LangGPT(提示链Prompt Chain)--提升模型鲁棒性
Prompt进阶系列5:LangGPT(提示链Prompt Chain)–提升模型鲁棒性
随着对大模型的应用实践的深入,许多大模型的使用者, Prompt 创作者对大模型的应用越来越得心应手。和 Prompt 有关的各种学习资料,各种优质内容也不断涌现。关于 Prompt 的实践…
StarCoder 2:GitHub Copilot本地开源LLM替代方案
GitHub CoPilot拥有超过130万付费用户,部署在5万多个组织中,是世界上部署最广泛的人工智能开发工具。使用LLM进行编程辅助工作不仅提高了生产力,而且正在永久性地改变数字原住民开发软件的方式,我也是它的付费用户之一。
低代码/…

Prompt进阶系列1:LangGPT(从编程语言反思LLM的结构化可复用提示设计框架)
Prompt进阶系列1:LangGPT(从编程语言反思LLM的结构化可复用提示设计框架) 大语言模型 (Large Language Models, LLMs) 在不同领域都表现出了优异的性能。然而,对于非AI专家来说,制定高质量的提示来引导 LLMs 是目前AI应用领域的一项重要挑战。现有的提示…
FAISS+bge-large-zh在大语言模型LangChain本地知识库中的作用、原理与实践
文章目录 FAISSbge-large-zh在大语言模型LangChain本地知识库中的作用、原理与实践引言FAISS与bge-large-zh简介FAISS原理bge-large-zh原理 FAISSbge-large-zh在LangChain本地知识库中的作用提高检索效率增强语义理解能力支持大规模数据处理 实践数据准备与处理FAISS索引构建与…

在 Mac M1 上运行 Llama 2 并进行训练
在 Mac M1 上运行 Llama 2 并进行训练 Llama 2 是由领先的人工智能研究公司 Meta (前Facebook)开发并发布的下一代大型语言模型 (LLM)。 它基于 2 万亿个公共数据 token 进行了预训练,旨在帮助开发人员和企业组织构建基于人工智能的生成工具和…

微调llama2模型教程:创建自己的Python代码生成器
本文将演示如何使用PEFT、QLoRa和Huggingface对新的lama-2进行微调,生成自己的代码生成器。所以本文将重点展示如何定制自己的llama2,进行快速训练,以完成特定任务。 一些知识点
llama2相比于前一代,令牌数量增加了40%࿰…

大语言模型对齐技术 最新论文及源码合集(外部对齐、内部对齐、可解释性)
大语言模型对齐(Large Language Model Alignment)是利用大规模预训练语言模型来理解它们内部的语义表示和计算过程的研究领域。主要目的是避免大语言模型可见的或可预见的风险,比如固有存在的幻觉问题、生成不符合人类期望的文本、容易被用来执行恶意行为等。
从必…
Self-attention与Word2Vec
Self-attention(自注意力)和 Word2Vec 是两种不同的词嵌入技术,用于将单词映射到低维向量空间。它们之间的区别: Word2Vec: Word2Vec 是一种传统的词嵌入(word embedding)方法,旨在为…
Llama2-Chinese项目:2.3-预训练使用QA还是Text数据集?
Llama2-Chinese项目给出pretrain的data为QA数据格式,可能会有疑问pretrain不应该是Text数据格式吗?而在Chinese-LLaMA-Alpaca-2和open-llama2预训练使用的LoRA技术,给出pretrain的data为Text数据格式。所以推测应该pretrain时QA和Text数据格式…

huggingface连接不上的解决方案
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法…
AI红娘开启约会新时代;网易云音乐Agent实践探索;微软生成式AI课程要点笔记;ComfyUI新手教程;图解RAG进阶技术 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 👀 Perplexity 官宣 7360 万美元B轮融资,打造世界上最快最准确的答案平台 https://blog.perplexity.ai/blog/perplexity-rais…
LLMs之Grok-1:model.py文件解读—实现了基于Transformer的预训练语言模型+利用JAX框架支持高性能分布式计算
LLMs之Grok-1:model.py文件解读—实现了基于Transformer的预训练语言模型+利用JAX框架支持高性能分布式计算 目录
model.py文件解读—实现了基于Transformer的预训练语言模型+利用JAX框架支持高性能分布式计算

Prompt-“设计提示模板:用更少数据实现预训练模型的卓越表现,助力Few-Shot和Zero-Shot任务”
Prompt任务(Prompt Tasks)
通过设计提示(prompt)模板,实现使用更少量的数据在预训练模型(Pretrained Model)上得到更好的效果,多用于:Few-Shot,Zero-Shot 等…

LLM:Transformers模型推理和加速
Pipeline
pipeline() 的作用是使用预训练模型进行推断。
不同类型的任务所下载的默认预训练模型可以在 Transformers 库的源码
[transformers/__init__.py at main huggingface/transformers GitHub]中的 SUPPORTED_TASKS 定义。
参数Parameters
Batch size
推理时没必…
AutoGPT、AgentGPT、BabyAGI、HuggingGPT、CAMEL:各种基于GPT-4自治系统总结
ChatGPT和LLM技术的出现使得这些最先进的语言模型席卷了世界,不仅是AI的开发人员,爱好者和一些组织也在研究探索集成和构建这些模型的创新方法。各种平台如雨后春笋般涌现,集成并促进新应用程序的开发。 AutoGPT的火爆让我们看到越来越多的自…

港大新工作 HiGPT:一个模型,任意关系类型 !
论文标题: HiGPT: Heterogeneous Graph Language Model
论文链接: https://arxiv.org/abs/2402.16024
代码链接: https://github.com/HKUDS/HiGPT
项目网站: https://higpt-hku.github.io/
1. 导读
异质图在各种领域…
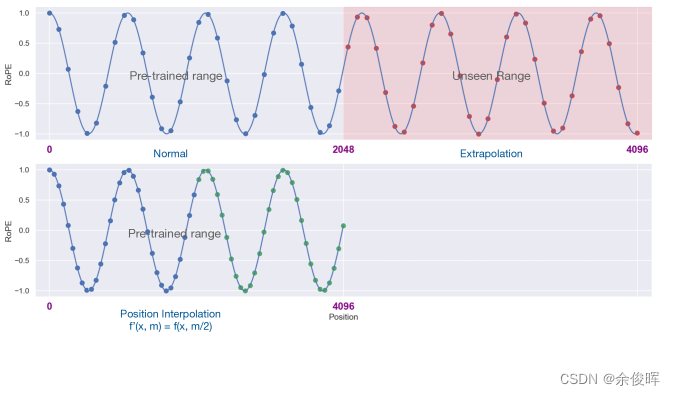
LLaMA长度外推高性价比trick:线性插值法及相关改进源码阅读及相关记录
前言
最近,开源了可商用的llama2,支持长度相比llama1的1024,拓展到了4096长度,然而,相比GPT-4、Claude-2等支持的长度,llama的长度外推显得尤为重要,本文记录了三种网络开源的RoPE改进方式及相…
如何基于LLMs使用LangChain构建强大的差异化应用--LangChain之初体验
近年来,语言模型(LMs)特别是LLMs已经成为最令人兴奋和最有影响力的技术之一。 它们可以为各种目的生成自然语言文本,例如回答问题、撰写摘要、创建故事等等。然而,仅使用LMs还不足以构建真正强大且与众不同的应用程序。您还需要: 将LMs连接到其他数据源,如文档、数据库、网…

【AI视野·今日NLP 自然语言处理论文速览 第七十五期】Thu, 11 Jan 2024
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 11 Jan 2024 Totally 36 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Leveraging Print Debugging to Improve Code Generation in Large Language Models Authors Xueyu Hu, Kun K…
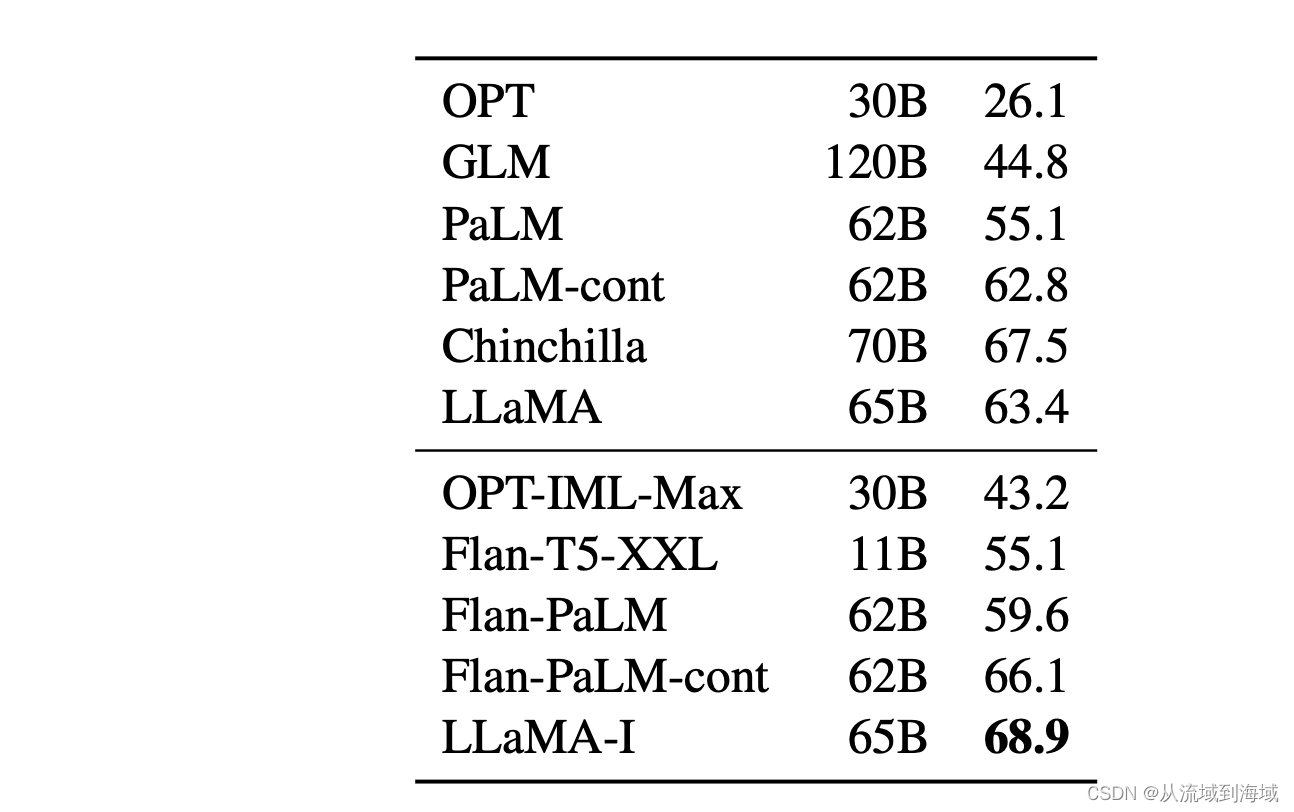
最强英文开源模型LLaMA架构探秘,从原理到源码
导读: LLaMA 65B是由Meta AI(原Facebook AI)发布并宣布开源的真正意义上的千亿级别大语言模型,发布之初(2023年2月24日)曾引起不小的轰动。LLaMA的横空出世,更像是模型大战中一个搅局者。虽然它…

大规模语言模型人类反馈对齐--PPO算法代码实践
在前面的章节我们已经知道,人类反馈强化学习机制主要包括策略模型、奖励模型、评论模型以及参考模型等部分。需要考 虑奖励模型设计、环境交互以及代理训练的挑战, 同时叠加大语言模型的高昂的试错成本。对于研究人员来说, 使用人类反馈强化学…
ChatGPT即将可以读取谷歌和微软的云盘数据为你管理私有数据!
ChatGPT的发展速度很快,在前面已经介绍过ChatGPT即将推出的Team订阅计划和新界面,包括对接自定义数据和自定义接口等。此外,DataLearnerAI还发现ChatGPT即将推出关联APP的能力,截图显示,目前已经测试了对接Google Driv…
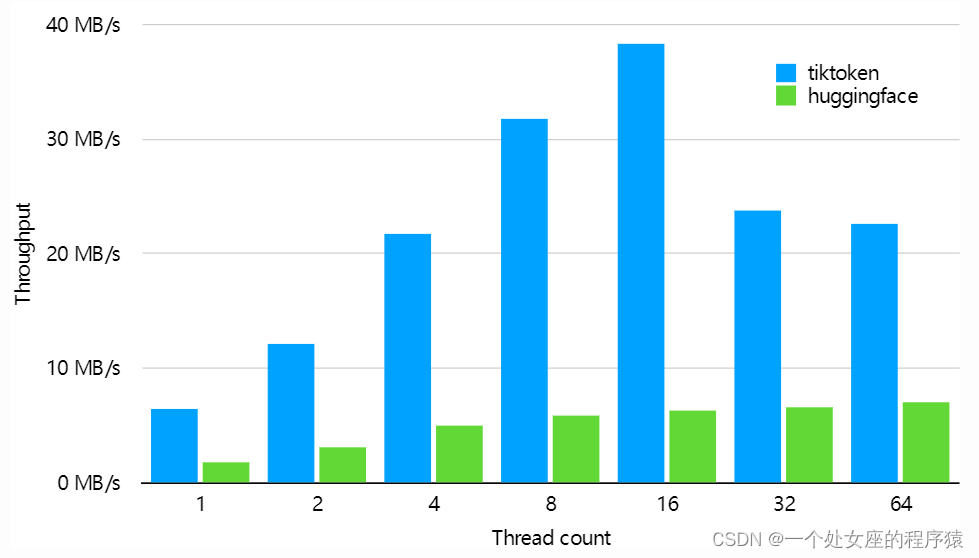
Py之tiktoken:tiktoken的简介、安装、使用方法之详细攻略
Py之tiktoken:tiktoken的简介、安装、使用方法之详细攻略 目录
tiktoken的简介
1、性能:tiktoken比一个类似的开源分词器快3到6倍
tiktoken的安装
tiktoken的使用方法
1、基础用法
(1)、用于OpenAI模型的快速BPE标记器
(2)、帮助可视化BPE过程的代…
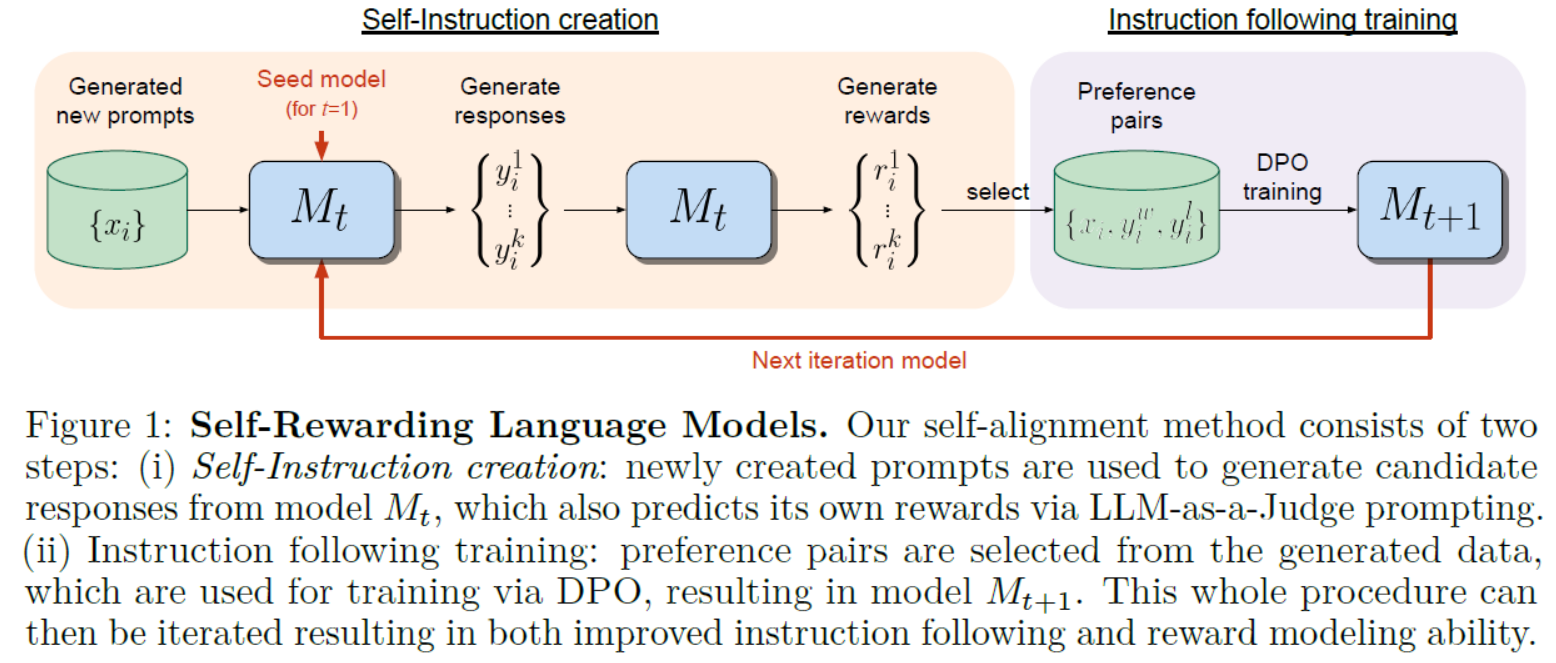
LLMs之Llama2 70B:《Self-Rewarding Language Models自我奖励语言模型》翻译与解读
LLMs之Llama2 70B:《Self-Rewarding Language Models自我奖励语言模型》翻译与解读 目录
《Self-Rewarding Language Models》翻译与解读
Abstract
5 Conclusion结论
6 Limitations限制 《Self-Rewarding Language Models》翻译与解读 地址 文章地址࿱…
【大模型应用开发教程】01_大模型简介
C1 大模型简介 一. 什么是LLM(大语言模型)?1. 发展历程2. 大语言模型的概念LLM的应用和影响 二、大模型的能力和特点1. 大模型的能力1.1 涌现能力(emergent abilities)1.2 作为基座模型支持多元应用的能力1.3 支持对话…
【ChatGLM2-6B】从0到1部署GPU版本
准备机器资源
显卡: 包含NVIDIA显卡的机器,如果是阿里云服务器可以选择ecs.gn6i-c4g1.xlarge规格硬盘: 大约50G左右操作系统: CentOS 7.9 64位CPU内存: 4C16G
更新操作系统
sudo yum update -y
sudo yum upgrade -y下载并安装anaconda
在命令行中,输…

AI大模型低成本快速定制秘诀:RAG和向量数据库
文章目录 1. 前言2. RAG和向量数据库3. 论坛日程4. 购票方式 1. 前言 当今人工智能领域,最受关注的毋庸置疑是大模型。然而,高昂的训练成本、漫长的训练时间等都成为了制约大多数企业入局大模型的关键瓶颈。 这种背景下,向量数据库凭借其独特…

AutoDL百川大模型体验
文章目录 镜像克隆模型下载测试效果AutoDL自定义服务 感谢AutoDL和CodeWithGPU这两个平台,让我们能低成本,低门槛地部署体验这些大模型 镜像克隆
我是在CodeWithGPU上克隆的这个镜像
模型下载 codewithgpu有介绍 注意这三个文件都需要下载 把那个&quo…

解决:ModuleNotFoundError: No module named ‘tiktoken’
解决:ModuleNotFoundError: No module named ‘tiktoken’ 文章目录 解决:ModuleNotFoundError: No module named tiktoken背景报错问题报错翻译报错位置代码报错原因解决方法方法一,直接安装方法二,手动下载安装方法三࿰…

【AI视野·今日NLP 自然语言处理论文速览 第八十四期】Thu, 7 Mar 2024
AI视野今日CS.NLP 自然语言处理论文速览 Thu, 7 Mar 2024 Totally 52 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
The Heuristic Core: Understanding Subnetwork Generalization in Pretrained Language Models Authors Adith…

如何使用 ChatGPT 进行编码和编程
文章目录 一、初学者1.1 生成代码片段1.2 解释功能 二、自信的初学者2.1 修复错误2.2 完成部分代码 三、中级水平3.1 研究库3.2 改进旧代码 四、进阶水平4.1 比较示例代码4.2 编程语言之间的翻译 五、专业人士5.1 模拟 Linux 终端 总结 大多数程序员都知道,ChatGPT …
AI大语言模型工程师学习路线
文章目录 运行LLMSLLM APIS开源的大语言模型Prompt engineering1. 明确目标2. 理解模型能力3. 使用示例4. 精确和具体的指令5. 考虑上下文6. 避免偏见和不准确的信息7. 测试和迭代8. 使用模板9. 考虑多语言能力10. 注意伦理和合规性结构化输出1. 使用明确的提示(Prompts)2. 采…
LLMs之FreeGPT35:FreeGPT35的简介、安装和使用方法、案例应用之详细攻略
LLMs之FreeGPT35:FreeGPT35的简介、安装和使用方法、案例应用之详细攻略 目录
FreeGPT35的简介
FreeGPT35的安装和使用方法
1、部署和启动服务
Node
2、使用 Docker 部署服务:
运行 Docker 容器以部署服务
使用 Docker Compose 进行更方便的容器化…

提示词4大经典框架;将AI融入动画工作流的案例和实践经验;构建基于LLM的系统和产品的模式;提示工程的艺术 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 🤖 高效提示词的4大经典框架:ICIO、CRISPE、BROKE、RASCEF ICIO 框架 Intruction (任务) :你希望AI去做的任务&am…
Amazon Generative AI 新世界 | 基于 Amazon 扩散模型原理的代码实践之采样篇
以前通过论文介绍 Amazon 生成式 AI 和大语言模型(LLMs)的主要原理之外,在代码实践环节主要还是局限于是引入预训练模型、在预训练模型基础上做微调、使用 API 等等。很多开发人员觉得还不过瘾,希望内容可以更加深入。因此&#x…
基于大语言模型的垂直领域知识问答系统流程学习
什么是垂直领域大语言模型应用
当前基于大模型的知识问答十分火热,大模型虽然能回答大多数通用问题,但在垂直领域中,回答的深度、准确度及时效性均有限。因此为了解决这一问题,可以结合“本地“知识结合大模型来解决。垂直领域即…
再薅!Pika全球开放使用;字节版GPTs免费不限量;大模型应用知识地图;MoE深度好文;2024年AIGC发展轨迹;李飞飞最新自传 | ShowMeAI日报
👀日报&周刊合集 | 🎡生产力工具与行业应用大全 | 🧡 点赞关注评论拜托啦! 👀 终于!AI视频生成平台 Pika 面向所有用户开放网页端 https://twitter.com/pika_labs Pika 营销很猛,讲述的「使…

【话题】ChatGPT等大语言模型为什么没有智能2
我们接着上一次的讨论,继续探索大模型的存在的问题。正巧CSDN最近在搞文章活动,我们来看看大模型“幻觉”。当然,本文可能有很多我自己的“幻觉”,欢迎批评指正。如果这么说的话,其实很容易得出一个小结论——大模型如…

序列模型(3)—— LLM的参数量和计算量
本文说明以下重要结论 设模型参数量为 N N N,训练数据量(Token)为 D D D,LLM训练中计算量(FLOPs) C ≈ 6 N D C\approx 6ND C≈6ND 参考: 模型训练计算量到底怎么算分析transformer模型的参数…

国内可用免费AI工具集
1、Kimi Chat 由月之暗面科技有限公司(Moonshot AI)开发的人工智能助手。擅长中英文对话,能够提供安全、有帮助且准确的回答。它的能力包括阅读和理解用户上传的文件,访问互联网内容,以及结合搜索结果来回答问题。比如…
LLM大语言模型(七):部署ChatGLM3-6B并提供HTTP server能力
目录 HighLight
部署ChatGLM3-6B并开启HTTP server能力
下载embedding模型bge-large-zh-v1.5
HTTP接口问答示例
LLM讲了个尴尬的笑话~ HighLight
将LLM服务化(如提供HTTP server能力),才能在其上构建自己的应用。
部署ChatGLM3-6B并开启…
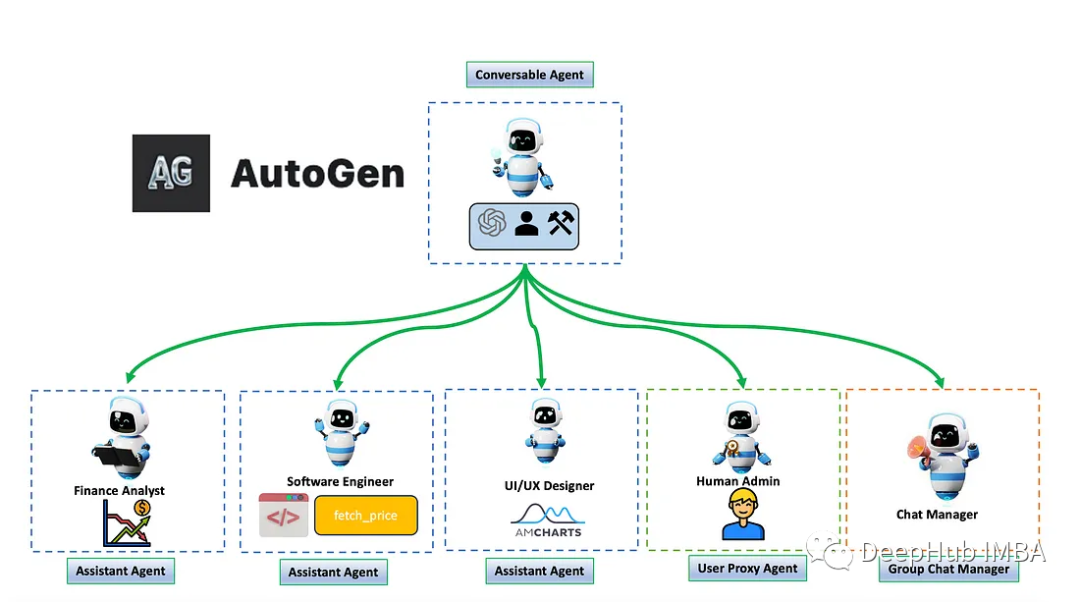
AutoGen多代理对话项目示例和工作流程分析
在这篇文章中,我将介绍AutoGen的多个代理的运行。这些代理将能够相互对话,协作评估股票价格,并使用AmCharts生成图表。
我们创建对话的目的是要求代理分析特定公司的股票价格,并制作股票价格图表。 为了实现这一目标,…
